In Amazon S3 (Simple Storage Service), duplicate objects refer to files or objects within single or multiple buckets with identical content. These duplicates might occur for various reasons, such as accidental uploads, numerous uploads of the same file, or synchronization processes.
It’s important to note that duplicate objects can increase storage costs since each object is billed separately based on size and storage duration. Therefore, it is generally recommended that duplicate objects be managed efficiently by avoiding them through proper naming conventions or using versioning when necessary.
Duplicate objects in AWS S3 can present several challenges and potential problems. Duplicate objects consume additional storage space, leading to higher storage costs. Keeping track of multiple copies of the same data can become challenging, especially in environments with frequent data uploads and updates. Many duplicate objects within an S3 bucket can impact performance, especially when listing, accessing, or managing objects. It may result in slower response times and increased latency for bucket operations. Duplicate objects may raise compliance and governance concerns, especially in regulated industries where data duplication can lead to issues with data retention policies, data privacy regulations, and audit requirements.
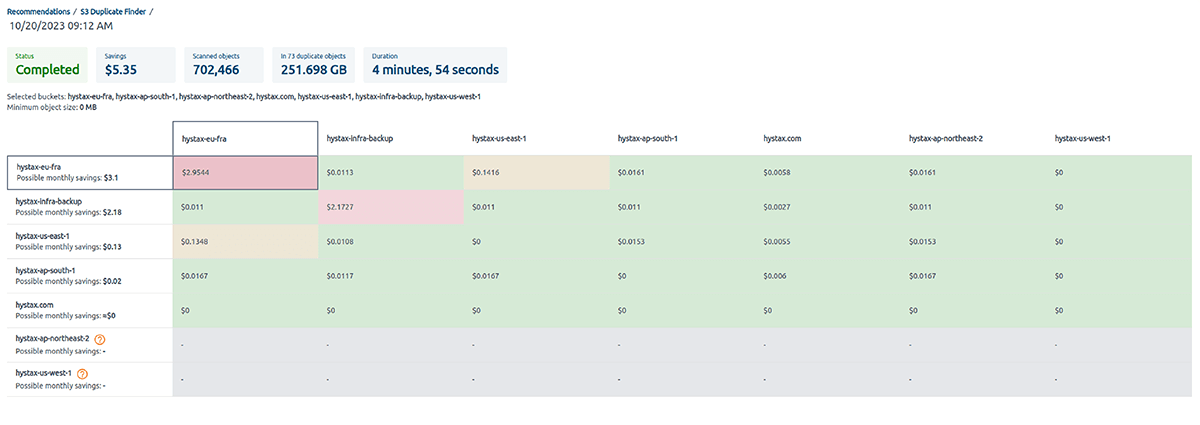
OptScale can help mitigate these problems. It’s essential to audit S3 buckets for duplicate objects regularly. Additionally, the tool can help identify and address duplicate objects proactively.
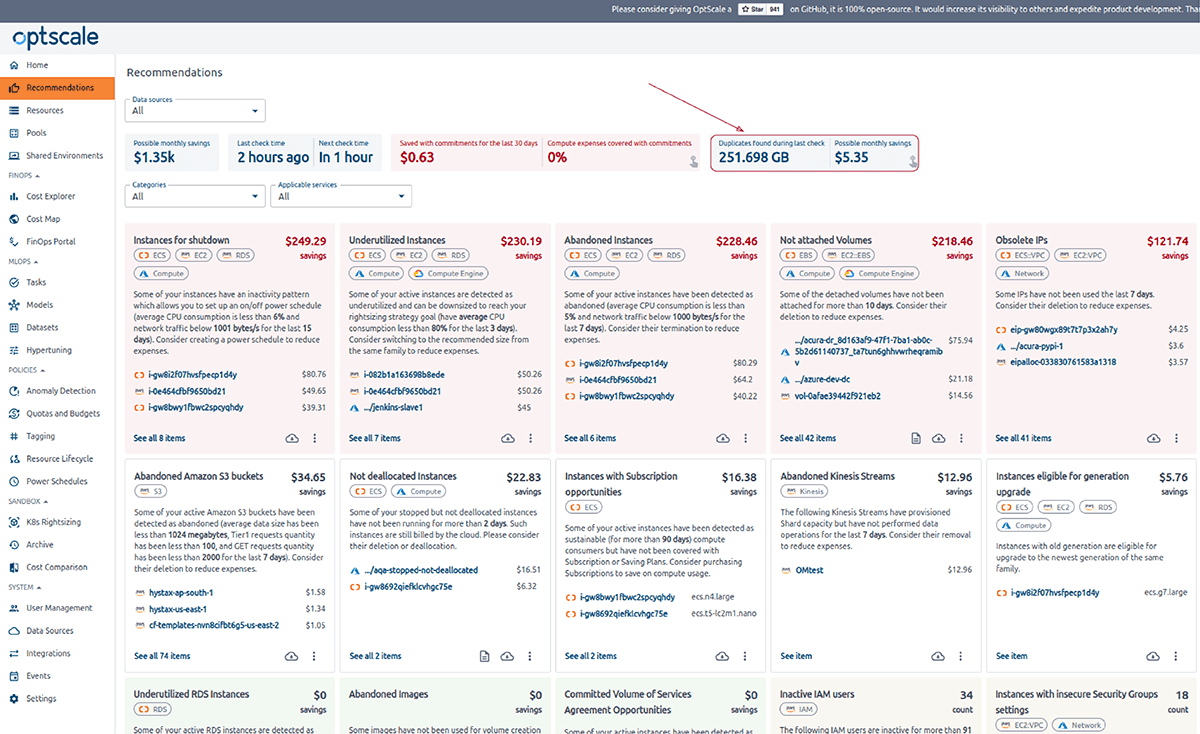
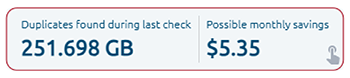
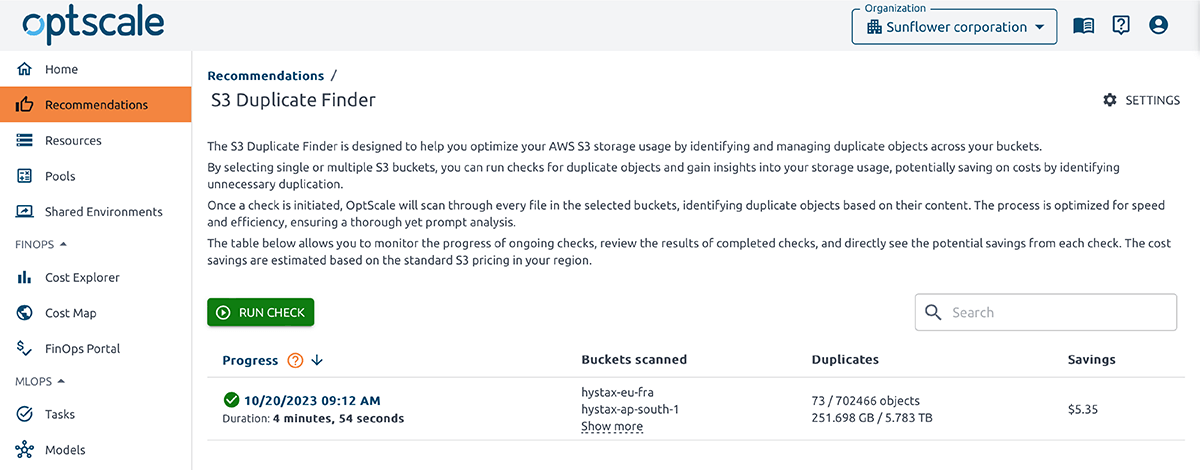
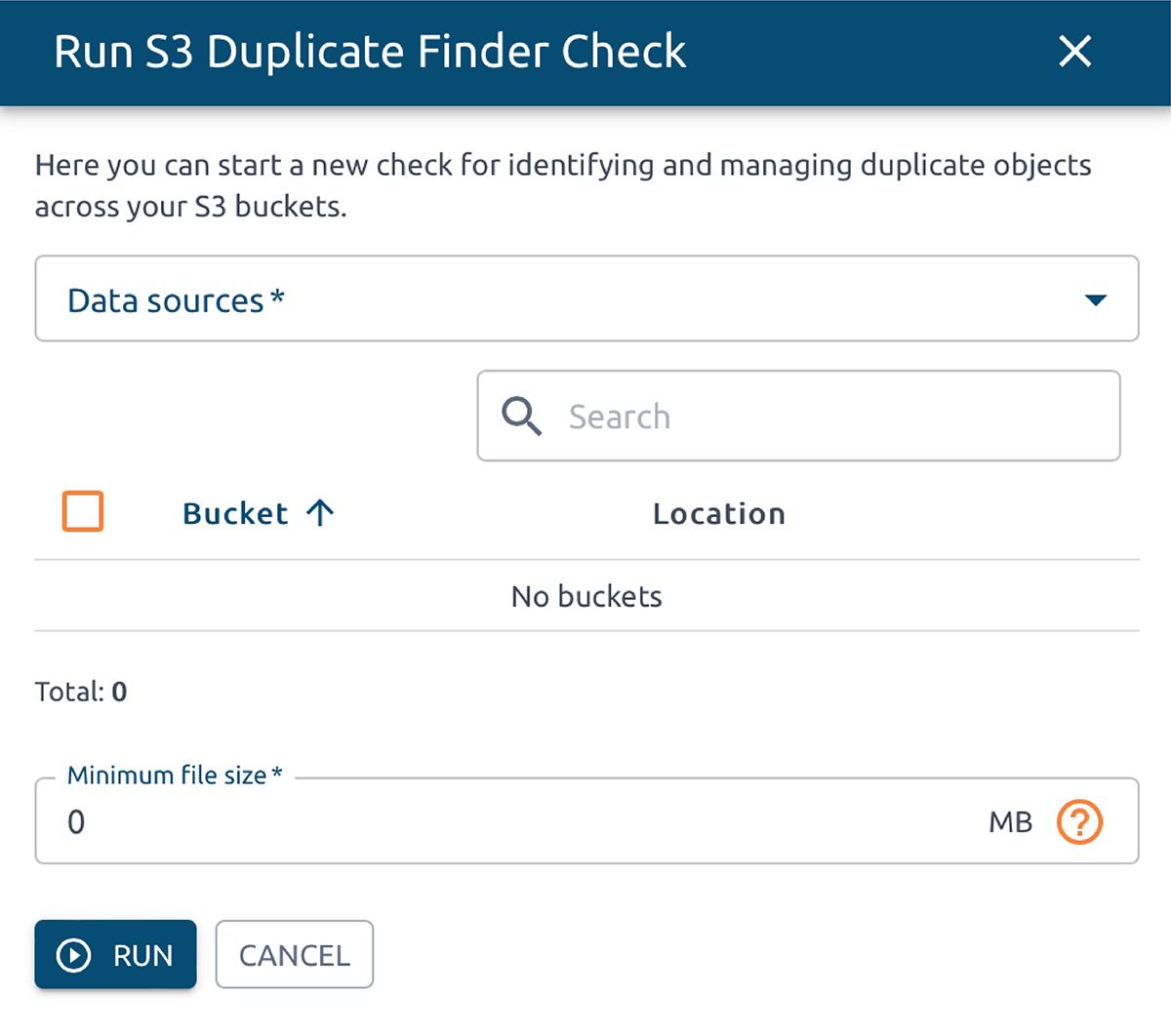
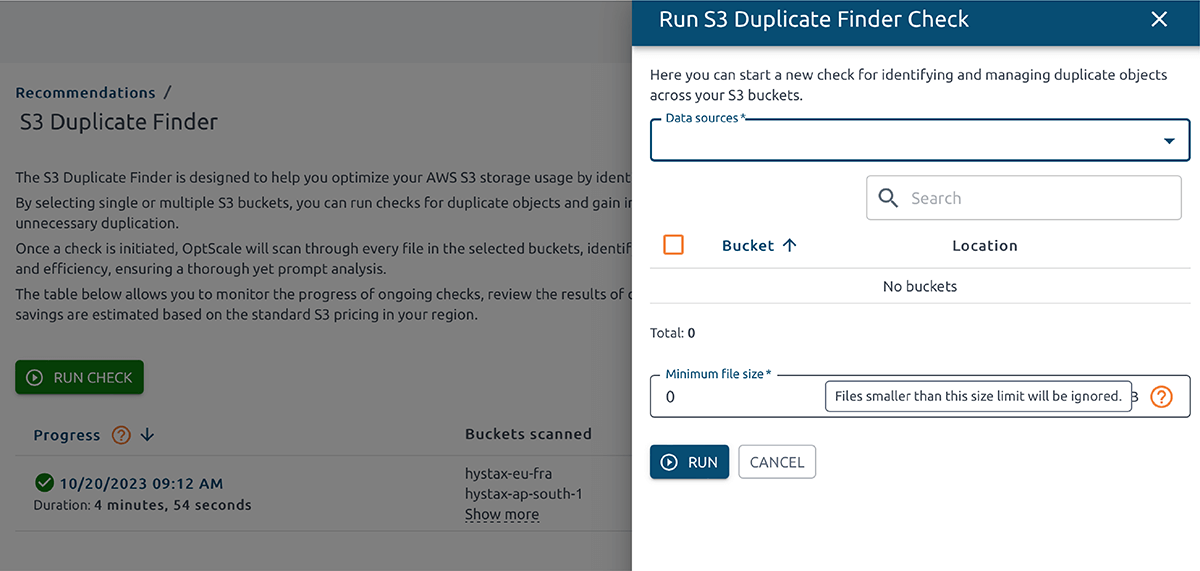
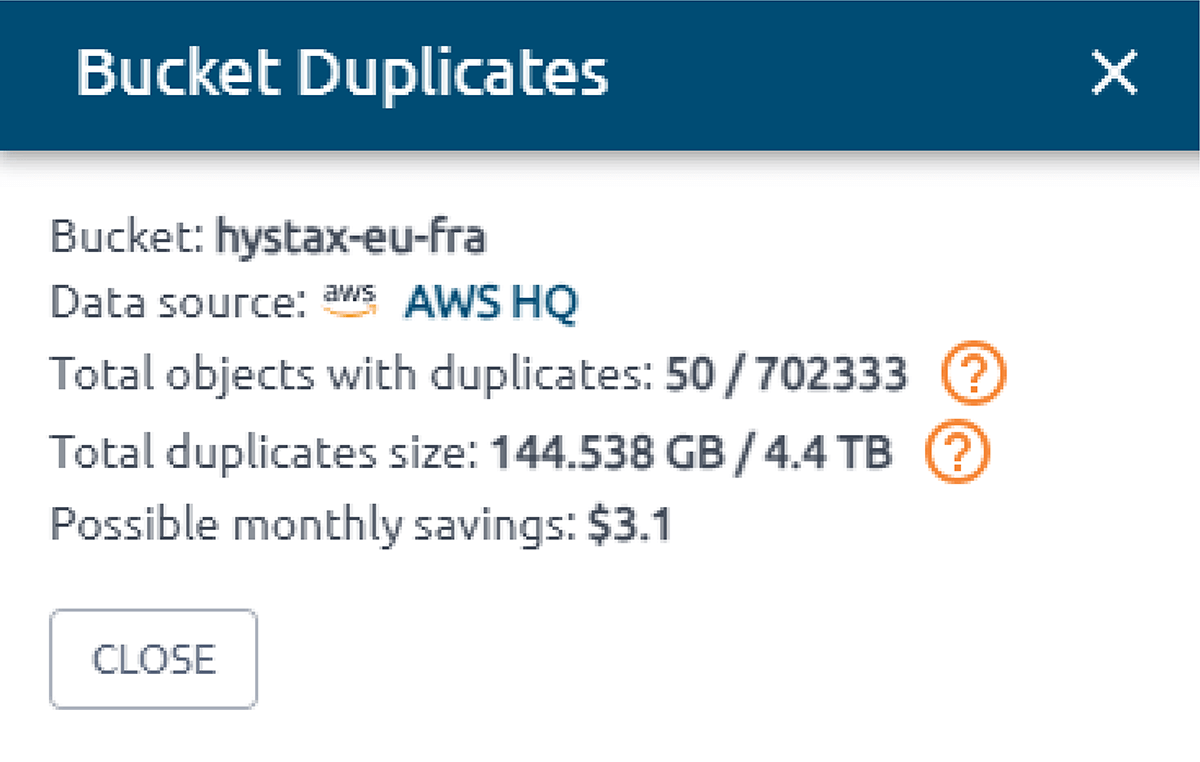
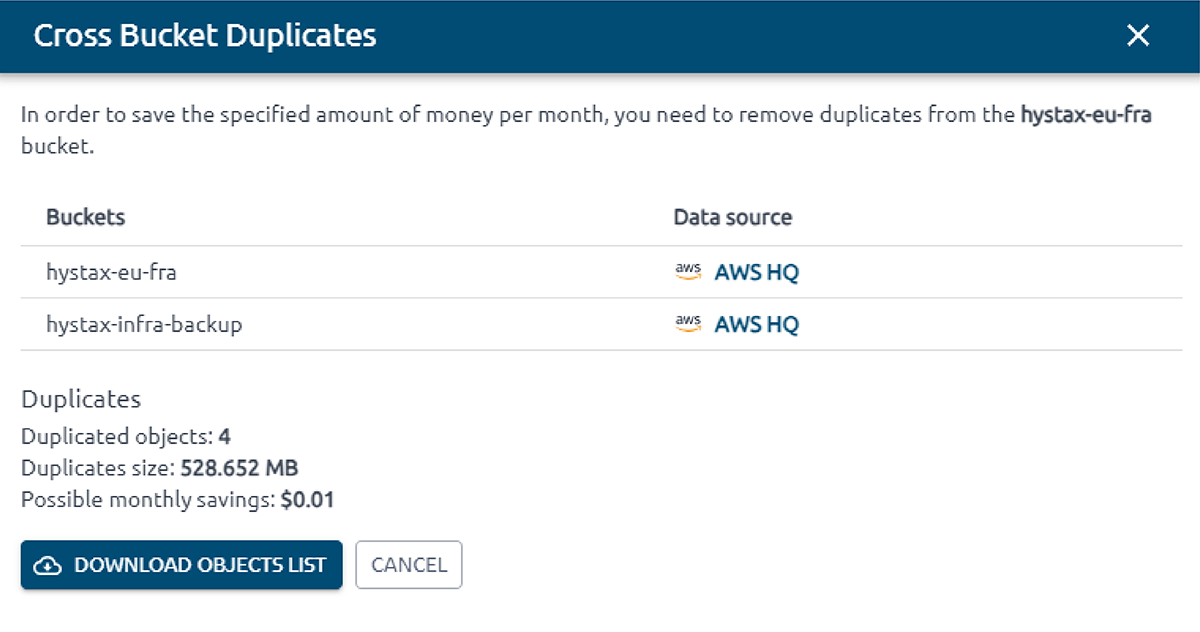
OptScale allows finding duplicate objects in AWS S3. The S3 Duplicate Finder (as it is called in the product) is designed to help you optimize your AWS S3 storage usage by identifying and managing duplicate objects across your buckets.
Selecting single or multiple S3 buckets allows you to run checks for duplicate objects and gain insights into your storage usage. By identifying unnecessary duplication, you can potentially save on costs.
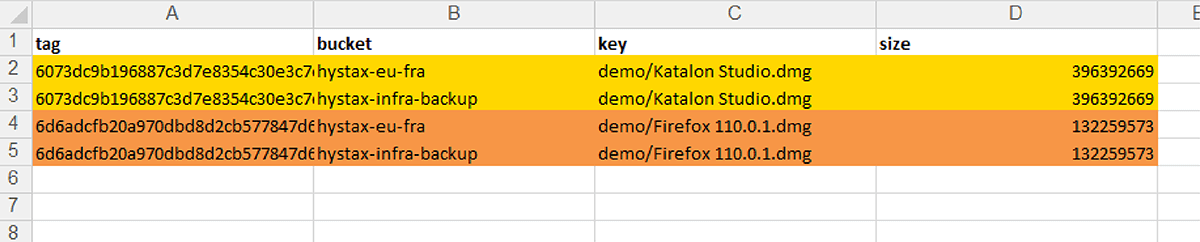
Once a check is initiated, OptScale will scan through every file in the selected buckets, identifying duplicate objects based on their content. The process is optimized for speed and efficiency, ensuring a thorough yet prompt analysis.