S3 Duplicate Finder#
Duplicate objects in AWS S3 can present several challenges and potential problems. They consume additional storage space, leading to higher storage costs. Use the OptScale S3 Duplicate Finder to optimize your AWS S3 storage usage by identifying and managing duplicate objects across your buckets.
Selecting single or multiple S3 buckets allows you to run checks for duplicate objects and gain insights into your storage usage. By identifying unnecessary duplication, you can potentially save on costs.
Once a check is initiated, OptScale will scan through every file in the selected buckets, identifying duplicate objects based on their content. The process is optimized for speed and efficiency, ensuring a thorough yet prompt analysis.
Summary cards#
To get a brief overview of duplicates, go to the Recommendations section of the menu and view the rightmost card in Summary cards.
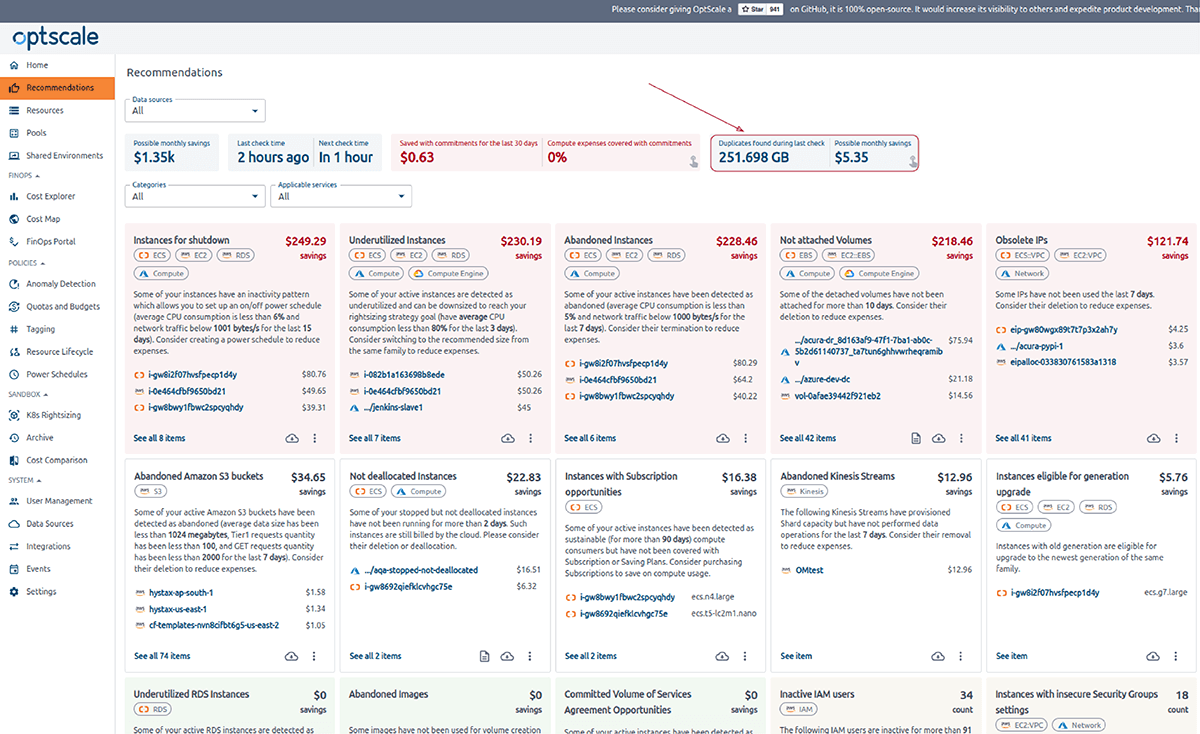
It displays duplicates found during the last check and potential monthly savings. The card may have different states depending on the conditions. The text S3 Duplicates: - indicates that no checks have been successfully completed or started. If the last check was successful, Duplicates found during last check and Possible monthly savings are displayed.
The card is clickable and leads you to the S3 Duplicate Finder page.
Page overview#
The S3 Duplicate Finder page showcases a table of all check launches, providing the option to initiate a new check, and configure settings.
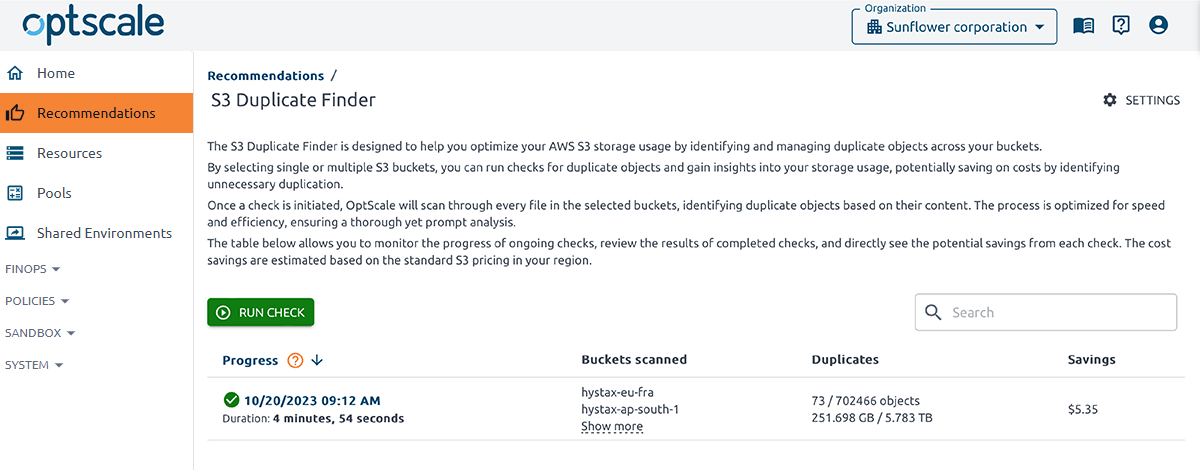
The tables present details, including the check’s initialization time, a list of scanned buckets with corresponding resource links, the total count of duplicated objects across all buckets, their sizes, and the overall savings:
-
The Progress column indicates the moment when a check was initiated and the current status of a specific check:
- Scheduled at <DateTime of Start> tells that the check has just been started. Wait until it is Completed to view information about duplicates.
 appears when the check is in progress and shows its duration.
appears when the check is in progress and shows its duration. shows that the check was successfully finished, displaying its total duration.
shows that the check was successfully finished, displaying its total duration. means that something went wrong. The reason can be found after Error:, and the full error message is displayed in a tooltip.
means that something went wrong. The reason can be found after Error:, and the full error message is displayed in a tooltip.
Refresh the page to get the valid run check status.
-
The Buckets Scanned column lists all the scanned buckets. By default, only the names of the first two scanned buckets are displayed in this column. Сlick the Show more button to view the remaining names.
-
The Duplicates column represents the number of duplicate objects found during a check.
-
The Savings column indicates the potential cost savings for removing the identified duplicates.
Click an item to view detailed information about the run check.
Actions#
Run check#
Note
Only a user with the Organization manager role can perform a run check.
1. To start a run check, go to Recommendations page → click the rightmost card in the Summary Cards section.
2. Click the Run check button to open a side modal.
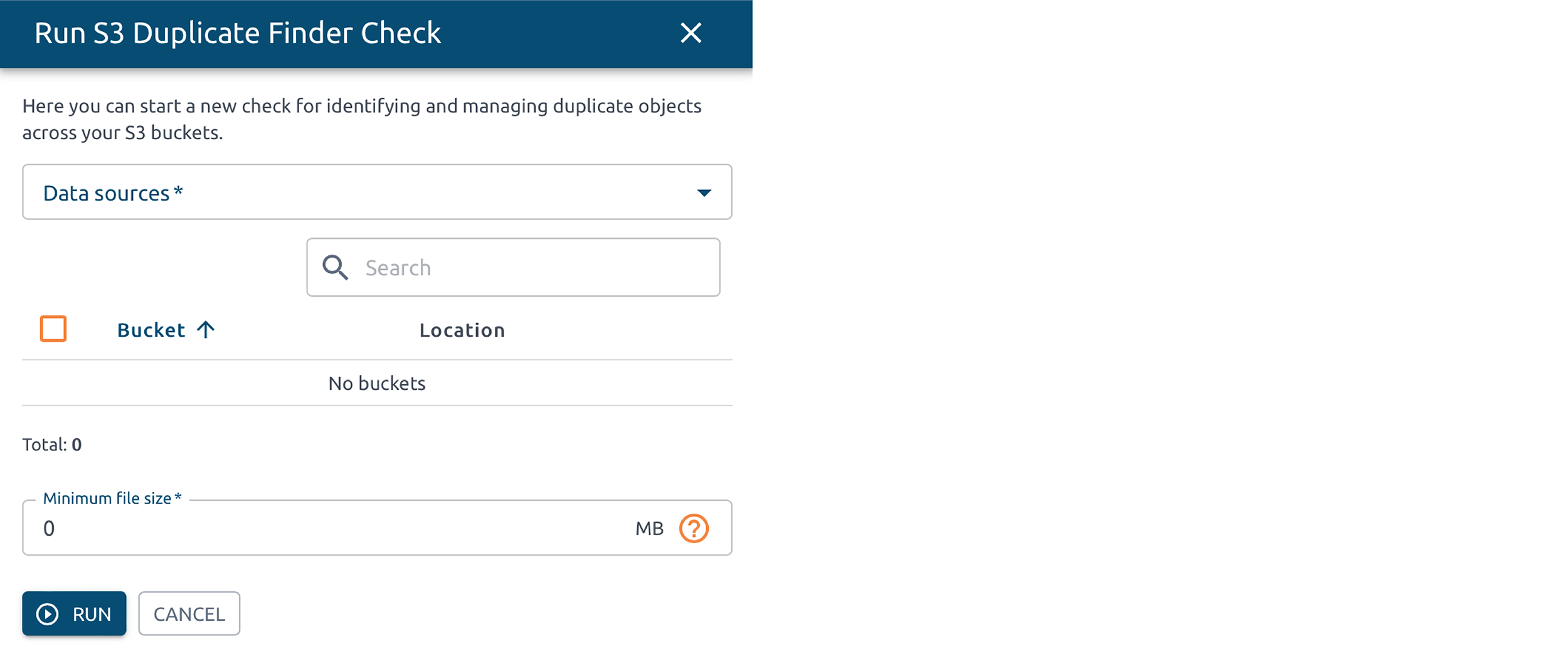
3. Configure and initiate a new check:
-
Select Data Sources.
-
Select Buckets. Note: the list of buckets is loaded based on the selected data sources.
-
Enter Minimum file size. Files bigger that the entered value include into the run check.
4. Click Run to start the check.
A new run check appears in the table marked as Scheduled at <DateTime of Start>. The check takes some time to complete. Wait until its status changes to Completed, then click it to view detailed information.
Update Settings#
Note
Only a user with the Organization manager role can update the settings.
1. To update settings, go to Recommendations page → click the rightmost card in the Summary Cards section.
2. Click the Settings button to open a side modal.

3. Set the threshold rules to colorize cells in the cross-duplicate matrix:
-
Requiring Attention: enter the expense threshold to mark savings that are equal to or greater than this value. In the cross-duplicate matrix, these savings are highlighted in yellow.
-
Critical: enter the expense threshold to mark savings that are equal to or greater than this value. In the cross-duplicate matrix, these savings are highlighted in red.
Note
An update to the thresholds affects all run checks.
4. Click Save.
Run check results overview#
Go to Recommendations page → click the rightmost card in the Summary Cards section.
Click the completed run check.
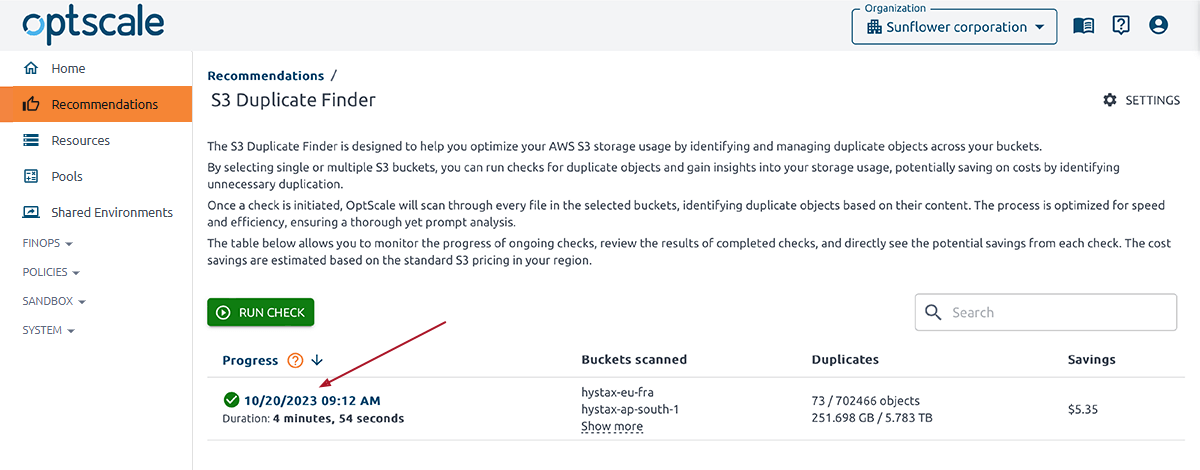
Check Summary Cards for general information, including total savings, the number of checked objects, the number of duplicate objects, and their size.
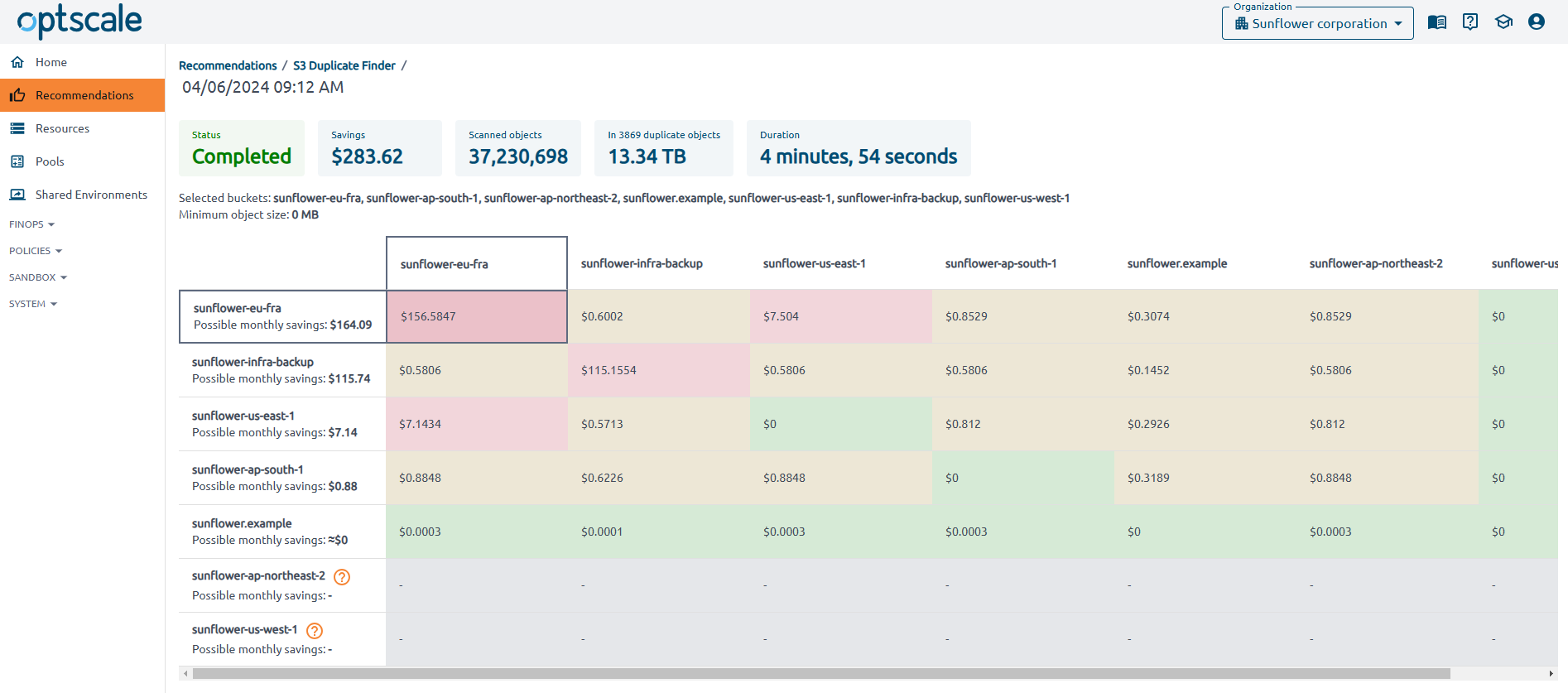
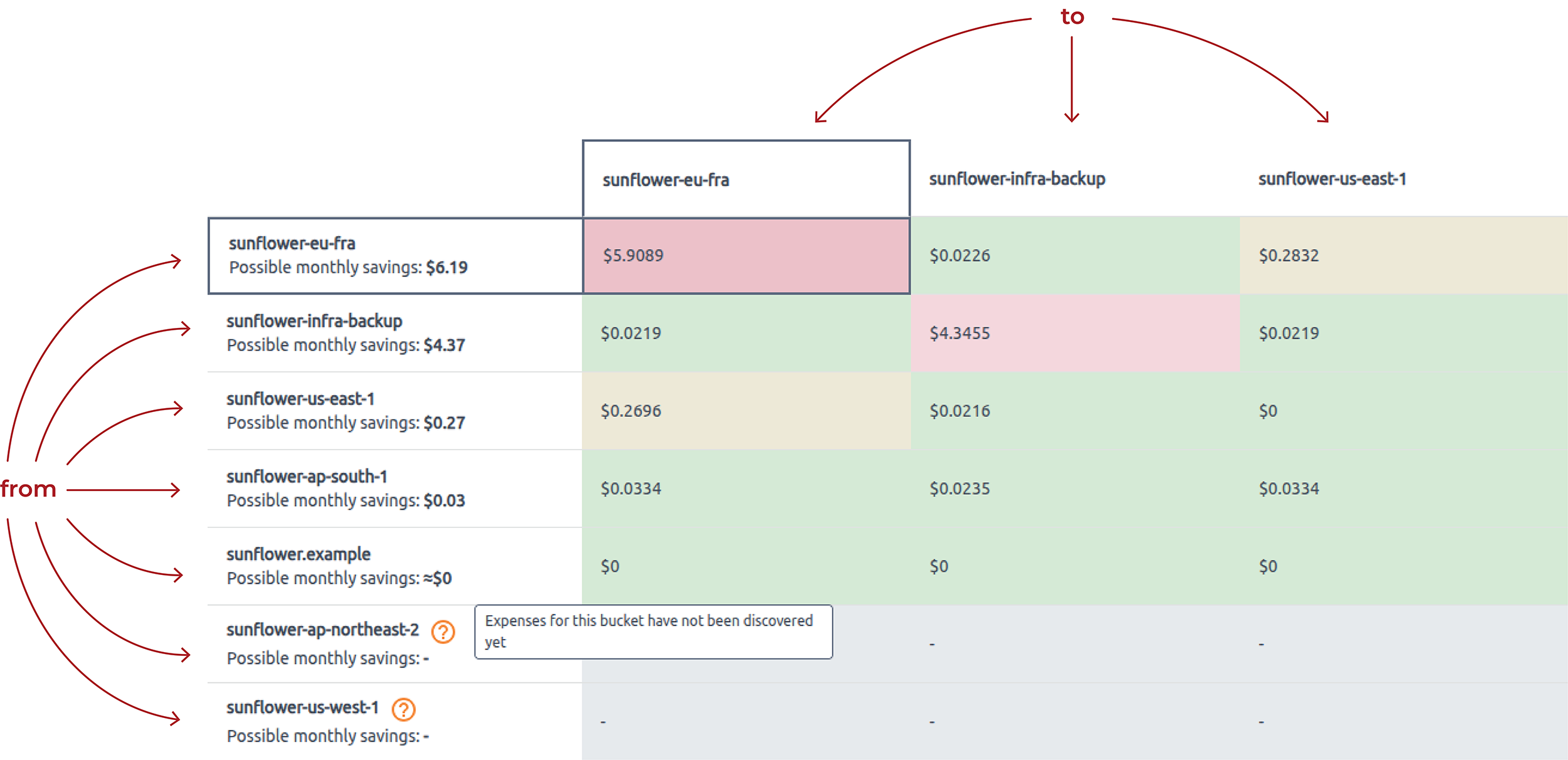
The cross-duplicate matrix displays the amount of duplicates between specific buckets. The From buckets are listed in the first column, while the To buckets appear in the first row. The intersections of rows and columns show potential monthly savings.
-
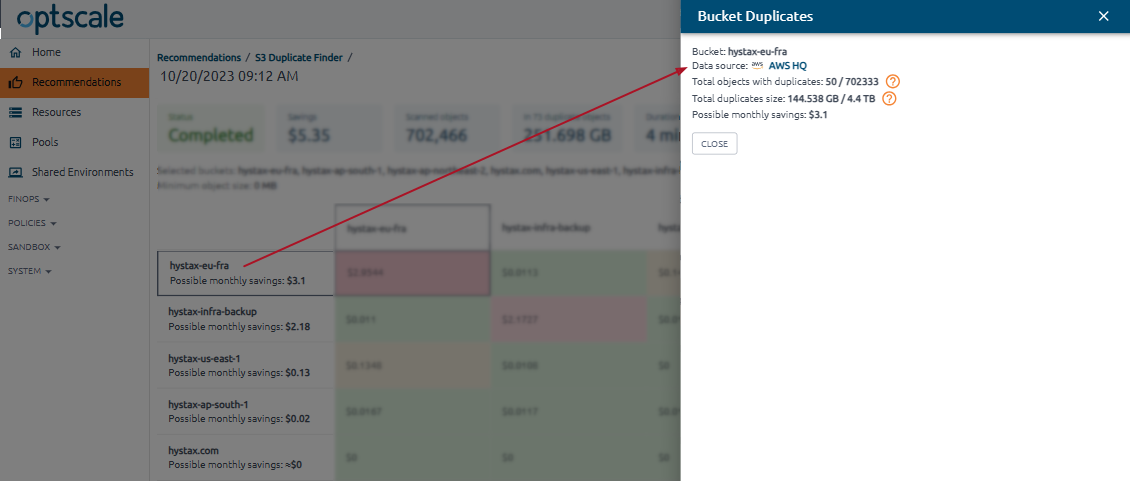
From display the bucket name and potential monthly savings. Each cell is clickable — use it to view the number and size of duplicate objects.
-
To display only bucket names.
-
Cross-cells (From-To intersection) display potential monthly savings.
-
Color scheme:
-
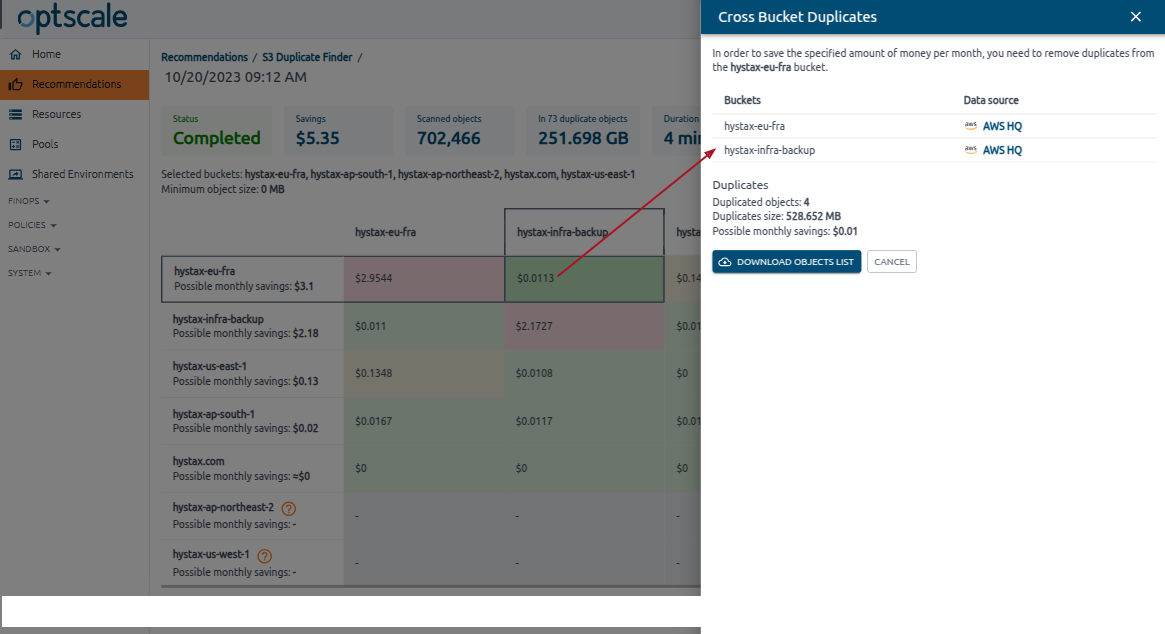
Click on a cross-cell to view the bucket list, duplicate size, potential savings, and download the objects list in the Cross Bucket Duplicates side modal.
 The object list is downloaded in .xlsx format. The file is structured to clearly display duplicates, the buckets they reside in, their paths (key column),
and their sizes. The tag column serves as a reference for identifying duplicates—objects with the same tag value are duplicates. By default, the table is
sorted by the tag column, ensuring easy-to-use data as soon as you open it.
The object list is downloaded in .xlsx format. The file is structured to clearly display duplicates, the buckets they reside in, their paths (key column),
and their sizes. The tag column serves as a reference for identifying duplicates—objects with the same tag value are duplicates. By default, the table is
sorted by the tag column, ensuring easy-to-use data as soon as you open it.
-