Recientemente leí un bonito... artículo Por el equipo de ingeniería de Intuit, donde mencionaron un tema interesante: la doble burbuja. En términos de nubes, es un estado durante migración a las nubes o transformación digital Cuando pagas por las nubes, los sitios de origen y destino. Analicemos lo común que es.
Un proyecto de migración a la nube estándar consta de un conjunto definido de pasos:
1. Justificación de TI y demostración de una necesidad empresarial. La justificación puede ser evitar la dependencia de un proveedor, el ciclo de renovación de la licencia de software o hardware del alquiler del centro de datos, la velocidad de escalado, el costo total de propiedad o el descuento de la nube pública, etc. Por lo general, cuando hay una justificación clara, no es un problema demostrar la necesidad empresarial.
2. Definición del alcance del proyecto. En este paso se define un responsable (director del proyecto) y aplicaciones/recursos específicos.
3. Fase de migración a la nube.
4. Autopsia.
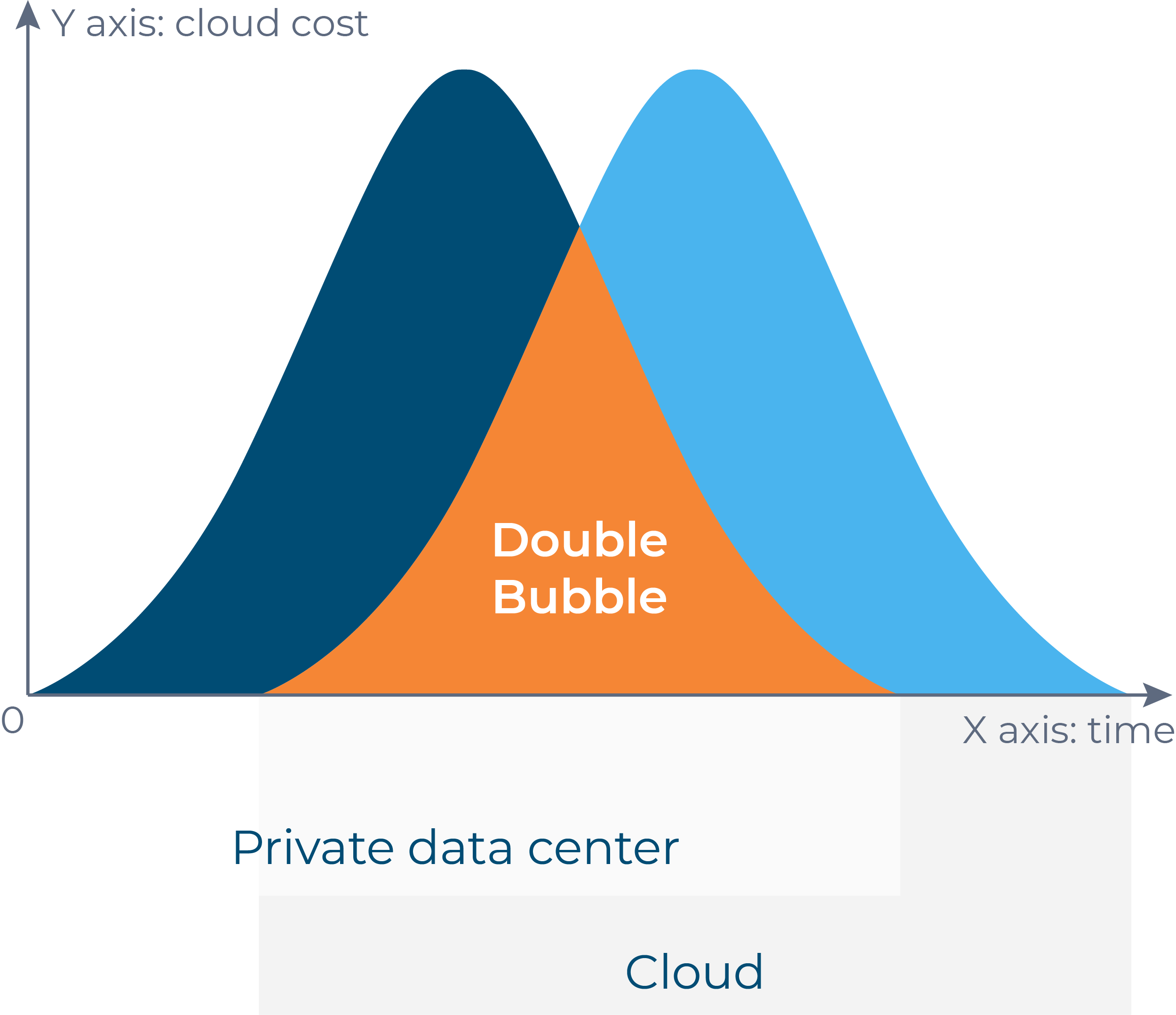
Por ahora, hablaremos solo de las páginas 2 y 3. Es normal que durante el proceso de migración haya momentos en los que haya recursos ejecutándose tanto en la nube de origen como en la de destino. Es posible que algunos de los recursos ya se hayan migrado, otros aún estén en cola o incluso no estén definidos para la migración y sigan ejecutándose en una nube de origen. Pero hay un caso interesante cuando se migran algunos recursos (en algunos casos, cientos o miles de máquinas) y hay que pagar por ellos dos veces.
Lograr una eficacia Gestión de costes Todo gira en torno a la optimización y el seguimiento. Con un conjunto de políticas, principios y procesos establecidos, las empresas pueden apaciguar a las partes interesadas y garantizar que sus gastos en la nube permanezcan bajo control. Si la factura de gastos en la nube le sorprende cada vez que la recibe, simplemente no está aprovechando todas las herramientas de gestión de costos que existen.
Cuando las empresas definen qué migrar a la nube, suelen pensar en categorías como aplicaciones, departamentos o recursos completos. Los consultores o proveedores de migración con experiencia siempre recomiendan dividir los recursos en bloques de 30 a 50 máquinas virtuales y migrar por fases. Esto reduce el riesgo y, además, ayuda a disipar las dudas. Lo ideal es que cada aplicación forme parte de un bloque. De esta manera, se puede migrar y probar toda la parte granular del sistema y evitar problemas de localización de datos. Recuerde que el tráfico en la nube entre regiones y el tráfico saliente no son gratuitos y resultan bastante caros. Es mejor tenerlo en cuenta antes de recibir la primera factura de la nube.
La causa principal de la burbuja está en el ámbito de "replicación -> pruebas" -> transferencia. Cuando se migra un fragmento, lleva un tiempo replicar los datos, definir cómo se obtendrán los incrementos (mejor de forma automatizada), probar el fragmento en una nube de destino y programar una ventana de mantenimiento para ejecutar la transferencia. Y esas tres fases forman la burbuja. Se almacenan los datos en dispositivos de bloques o almacenamiento de objetos, se ejecutan máquinas virtuales en una nube de destino y se paga por el procesamiento. En la mayoría de los casos, las migraciones de prueba pueden durar entre 1 y 3 semanas (pueden ser incluso más) hasta que un equipo que posee la aplicación migrada valida que todo está bien con ella en una nube de destino y que no hay degradación del rendimiento ni otros problemas. Y si se migran varios fragmentos en paralelo, la burbuja crecerá.
Entonces, ¿cómo evitar la burbuja?
1. En primer lugar, identifica tu ritmo de migración. Sé muy franco contigo mismo. Así es exactamente como se aprende una nueva habilidad: muy lentamente al principio y mucho mejor después de unas cuantas iteraciones.
2. Defina una cola de aplicaciones o fragmentos. Incluya esta información en el calendario de su proyecto de migración.
3. Descubra una forma de replicar las máquinas virtuales sin tiempos de inactividad y sin tener que volver a replicarlas constantemente. Hay docenas de herramientas que lo hacen, lo que le permite ahorrar tiempo y dinero, ya que paga menos por el almacenamiento.
4. Comuníquese con los equipos que poseen los fragmentos o las aplicaciones. Defina con ellos los criterios de aceptación y el proceso de migración. Cuanto antes empiecen a pensar en ello, más preparados estarán cuando llegue el momento. Defina los intervalos de tiempo en los que deben probar la migración. Este es el paso más importante, ya que las pruebas son el punto débil y, por lo general, los equipos no tienen idea de cómo probar las aplicaciones, cuáles son los componentes o quién es el propietario de cada máquina.
5. Defina el período de espera: cuánto tiempo debe esperar hasta eliminar las máquinas virtuales migradas del entorno de origen. No olvide que necesita un plan de respaldo si algo sale mal con las máquinas virtuales y las aplicaciones en una nube de destino, y aún paga (directa o indirectamente) por las máquinas en el lado de origen.
6. Interrumpa las pruebas tan pronto como vea que el equipo no está preparado o que no es su prioridad. Si no están motivados, simplemente perderán tiempo (equivalente a dinero en nubes públicas) o, peor aún, tomarán una decisión (aceptar o rechazar) en función de algún criterio extraño y procederán a utilizar las máquinas en una nube de origen o se darán cuenta de que hubo problemas cuando las máquinas virtuales de origen ya se habrían eliminado. Reitere el tema con su gerente o la alta gerencia para ajustar las prioridades de ambos equipos.
7. Si las pruebas se aprueban, proceda con la migración. Elimine todas las instantáneas y las migraciones de prueba de las aplicaciones migradas. Recuerde iniciar el cronómetro para el tiempo de espera.
8. Revise sus estimaciones de ritmo y ajuste su cronograma.
Tendrás Una especie de doble burbuja en cualquier migración. proyecto, pero se puede controlar su tamaño mediante una planificación y una comunicación adecuadas con los propietarios de las aplicaciones y las máquinas virtuales. Solo las personas valientes migran toda la infraestructura en una sola ejecución; las personas inteligentes planifican y lo hacen en partes y fases.