Please consider giving OptScale aStar on GitHub, it is 100% open source. It would increase its visibility to others and expedite product development. Thank you!
Joint Webinar + Live Demo: From VMware or any cloud to CloudSigma – automated migration made simple. Watch the replay
Webinar + live demo: Hystax Acura for Managed Service Providers – Disaster Recovery and Backup for thousands of customers. Watch the replay
How much is your company actually spending on AI this month?
Cut it by 60%. Govern every AI prompt and agent. Learn more on optscale.ai
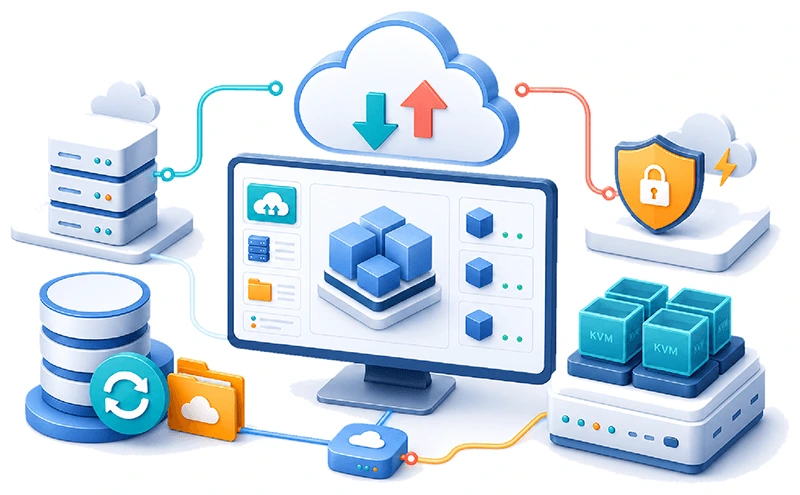
Any-to-any cloud migration. VMware to any KVM platform
Migrate all types of workloads between any cloud platforms, including VMware to any KVM platform quickly, effortlessly, and securely.
Hystax Acura provides users with a fully automated migration process, with consistent background replication and instant workload launch on the target site. Network traffic compression and deduplication during replication significantly reduce both the time required for data transfer and the use of cloud resources.
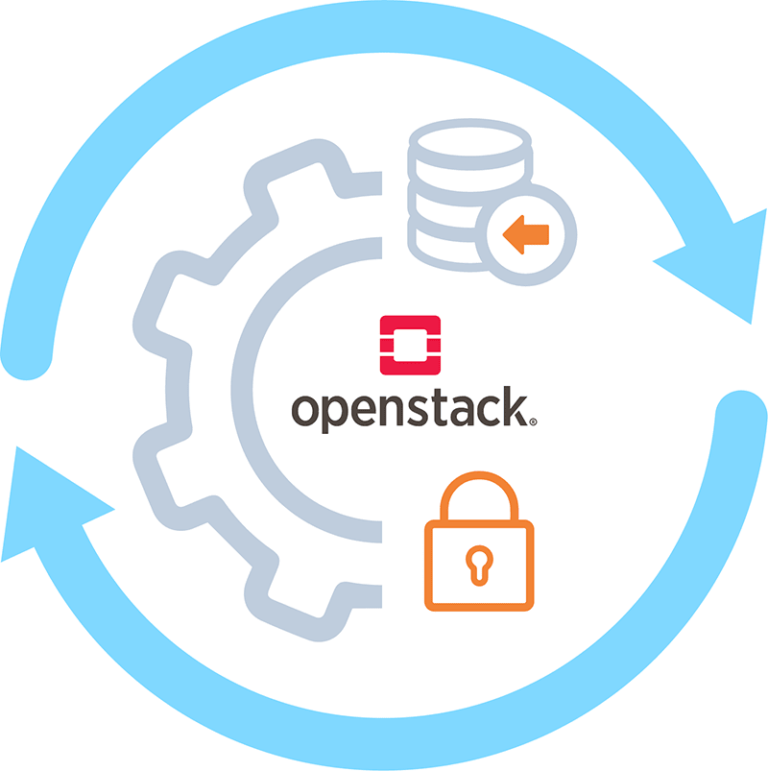
Perform disaster recovery or backup for OpenStack to restore all types of workloads and applications without any data loss and downtime.
With Hystax Acura, companies get full disaster recovery automation. The solution offers users an agentless replication process, low RPO and RTO values, and protected data retention in block devices.
Hystax Acura provides the ability to replicate OpenStack infrastructure settings and recreate them on the OpenStack receiver: tenants, subnets, and flavors.
Explore fully automated Hystax Acura software that allows you to securely attain robust IT Resilience and ensure uninterrupted Business Continuity with low RPO and RTO values
Hystax has joined the OpenInfra Foundation to support open infrastructure adoption and help organizations migrate VMware workloads to OpenStack safely, efficiently, and with minimal disruption.