En Amazon S3 (Simple Storage Service), los objetos duplicados hacen referencia a archivos u objetos dentro de uno o varios depósitos con contenido idéntico. Estos duplicados pueden producirse por diversos motivos, como cargas accidentales, numerosas cargas del mismo archivo o procesos de sincronización.
Es importante tener en cuenta que los objetos duplicados pueden aumentar costos de almacenamiento Dado que cada objeto se factura por separado en función del tamaño y la duración del almacenamiento, se recomienda en general gestionar de forma eficiente los objetos duplicados, evitándolos mediante convenciones de nombres adecuadas o utilizando el control de versiones cuando sea necesario.
Los objetos duplicados en AWS S3 pueden presentar varios desafíos y problemas potenciales. Los objetos duplicados consumen espacio de almacenamiento adicional, lo que genera mayores costos de almacenamiento. Realizar un seguimiento de varias copias de los mismos datos puede volverse un desafío, especialmente en entornos con actualizaciones y cargas de datos frecuentes. Muchos objetos duplicados dentro de un depósito de S3 pueden afectar el rendimiento, especialmente al enumerar, acceder o administrar objetos. Puede generar tiempos de respuesta más lentos y una mayor latencia para las operaciones del depósito. Los objetos duplicados pueden generar inquietudes sobre cumplimiento y gobernanza, especialmente en industrias reguladas donde la duplicación de datos puede generar problemas con las políticas de retención de datos, las regulaciones de privacidad de datos y los requisitos de auditoría.
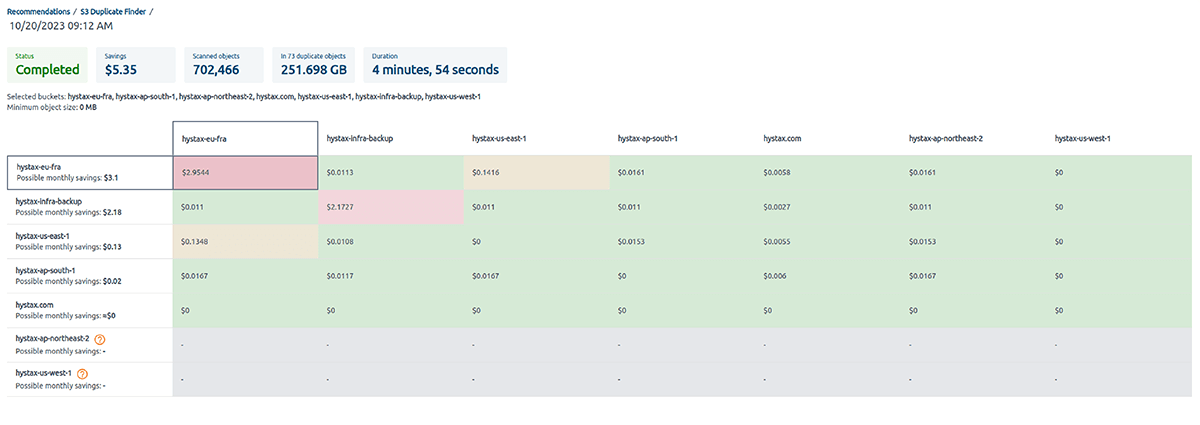
OptScale puede ayudar a mitigar estos problemas. Es fundamental auditar periódicamente los depósitos de S3 para detectar objetos duplicados. Además, la herramienta puede ayudar a identificar y abordar los objetos duplicados de forma proactiva.
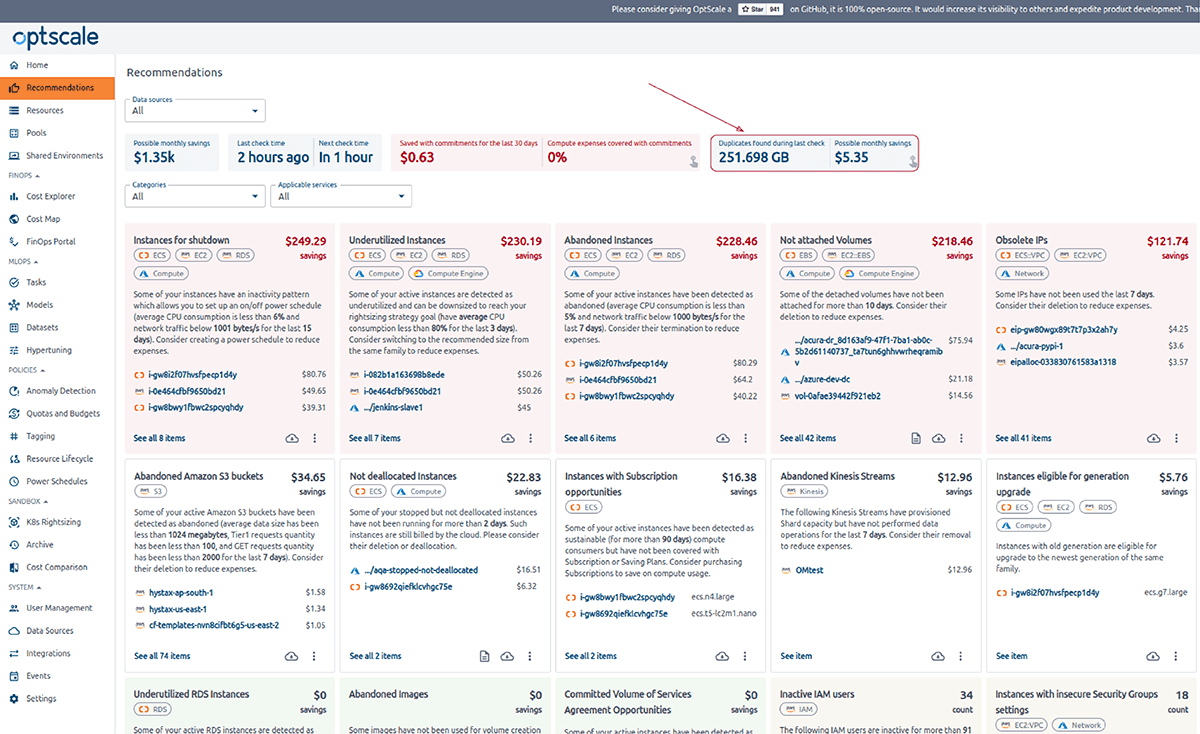
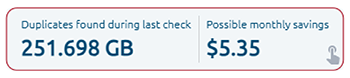
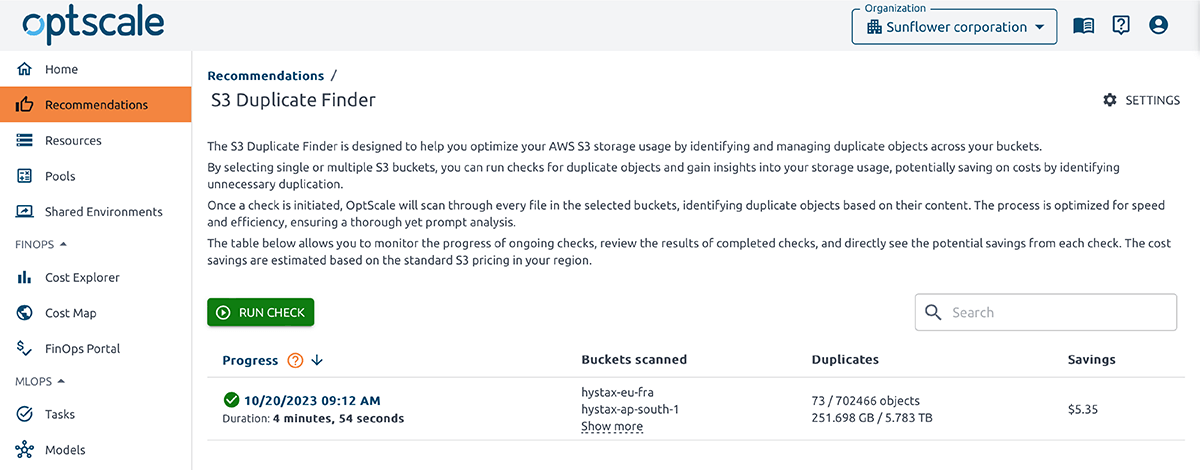
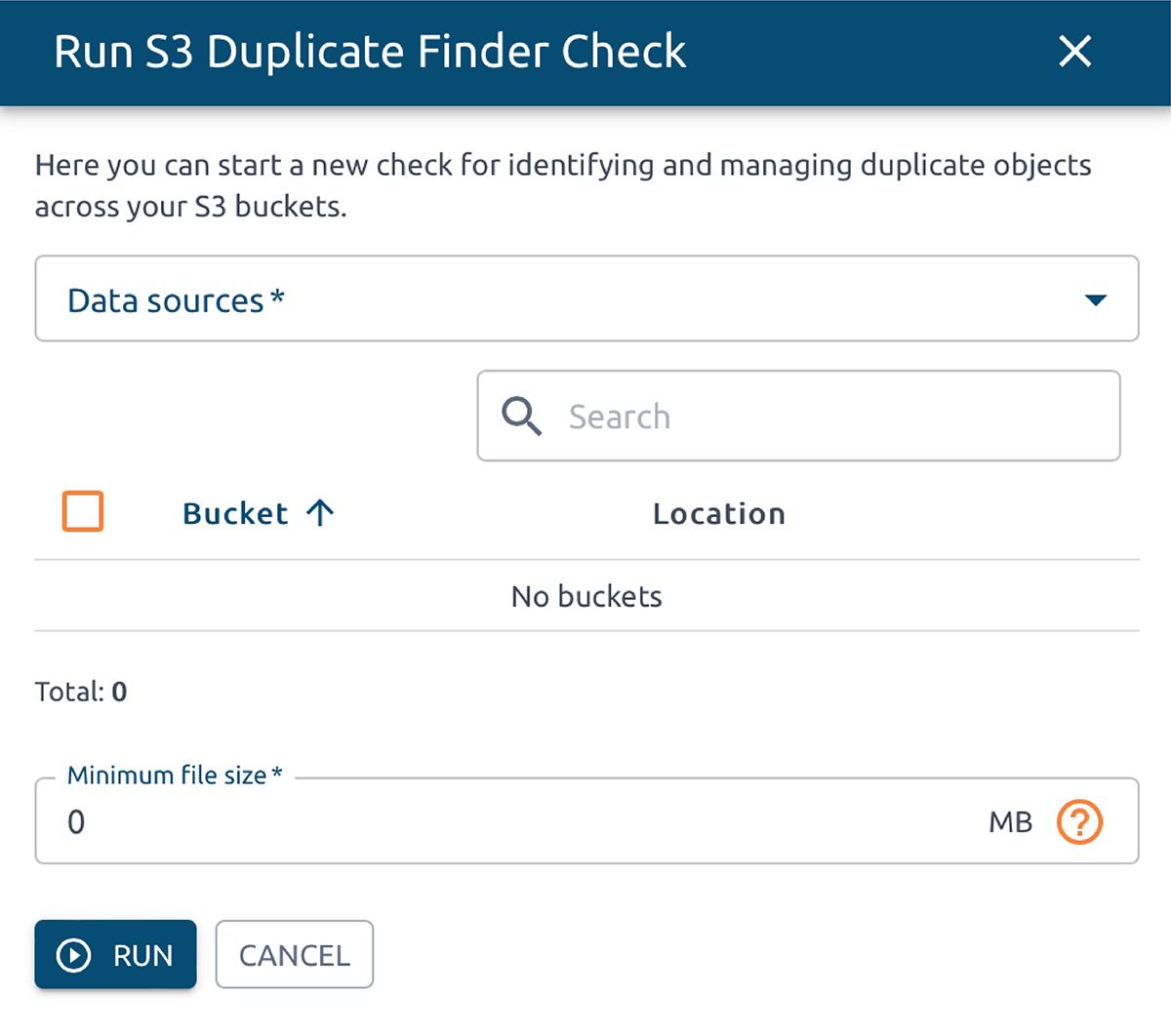
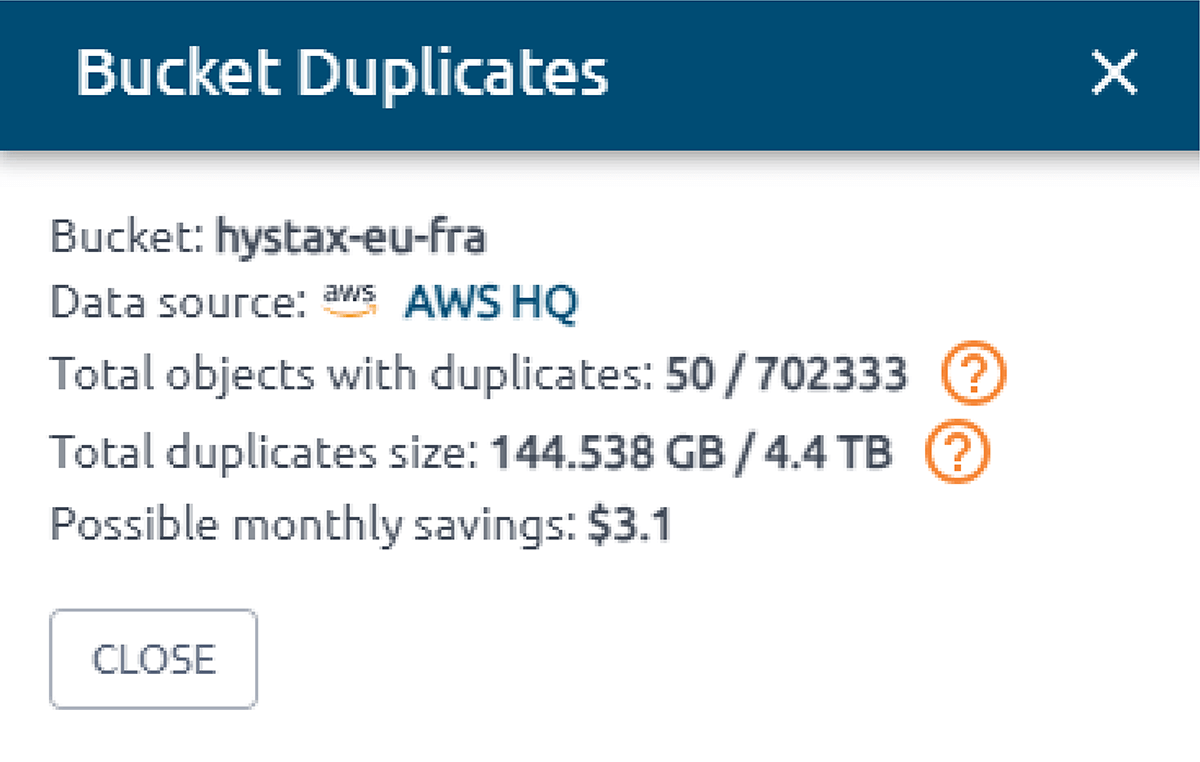
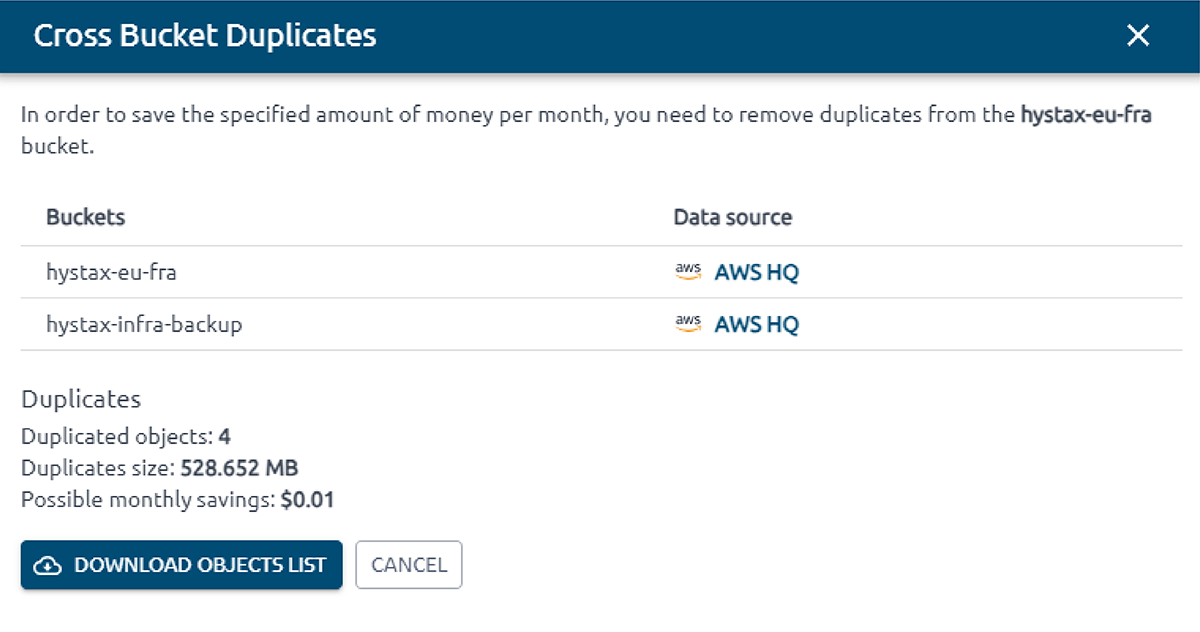
OptScale permite encontrar objetos duplicados en AWS S3. El Buscador de duplicados de S3 (como se lo llama en el producto) está diseñado para ayudarlo a optimizar el uso del almacenamiento de AWS S3 mediante la identificación y la administración de objetos duplicados en todos sus depósitos.
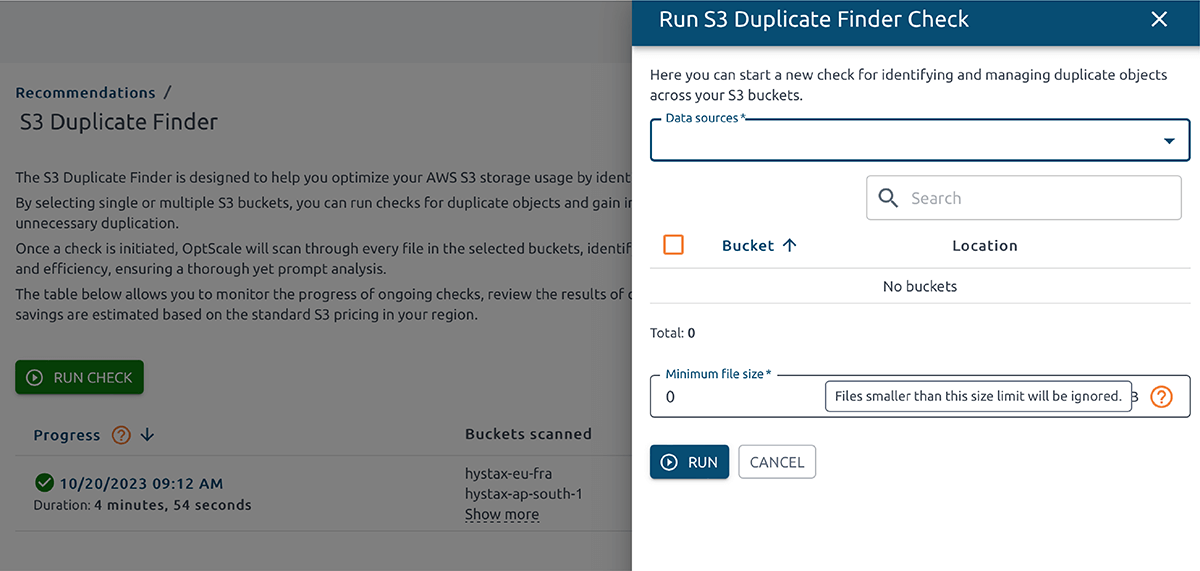
La selección de uno o varios depósitos S3 le permite ejecutar comprobaciones de objetos duplicados y obtener información sobre el uso del almacenamiento. Al identificar duplicaciones innecesarias, puede ahorrar costos.
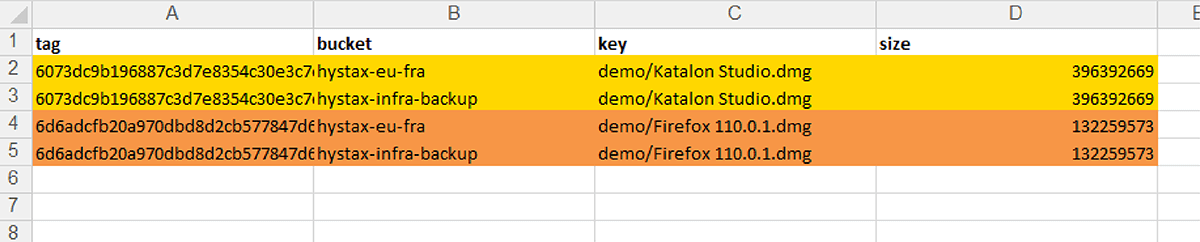
Una vez que se inicia una verificación, OptScale escaneará cada archivo en los contenedores seleccionados e identificará objetos duplicados según su contenido. El proceso está optimizado para lograr velocidad y eficiencia, lo que garantiza un análisis exhaustivo y rápido.