Las partes principales del esquema, que describe los procesos clave de MLOps, son bloques horizontales, dentro de los cuales se describen los aspectos procedimentales de MLOps (se les asignan las letras A, B, C, D). Cada uno de ellos está diseñado para resolver tareas específicas en el marco de garantizar el funcionamiento ininterrumpido de los servicios de ML de la empresa. Para comprender mejor el esquema, sería bueno comenzar con Experimentación.
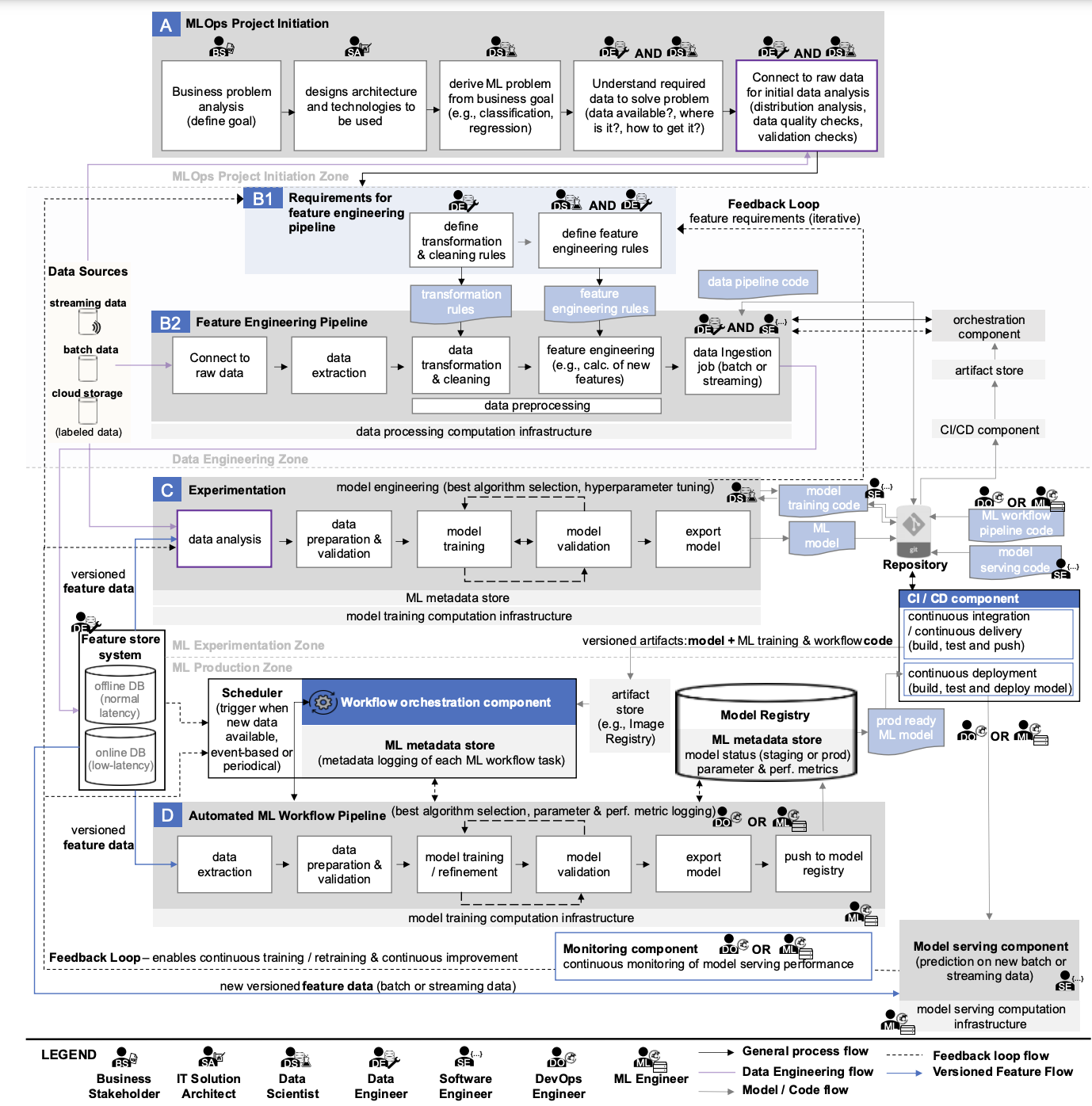
Experimentación, o el proceso de realizar experimentos.
Si una empresa cuenta con servicios de ML, entonces hay empleados trabajando en Jupyter. En muchas empresas, todos los procesos de desarrollo de ML se concentran en esta herramienta. Es aquí donde comienzan la mayoría de las tareas, para las cuales es necesario implementar prácticas de MLOps.
Por ejemplo, la empresa A tiene la necesidad de automatizar parte de un proceso mediante el aprendizaje automático (supongamos que el departamento y los especialistas pertinentes están disponibles). Es poco probable que la solución a la tarea se conozca de antemano. Por lo tanto, los desarrolladores deben estudiar la tarea y probar posibles formas de implementarla.
Para este propósito, un ingeniero/desarrollador de ML escribe código para varias implementaciones de tareas y evalúa los resultados obtenidos en comparación con los métricas objetivoEsto casi siempre se hace en Jupyter Lab. De esta forma, es necesario registrar manualmente mucha información importante y luego comparar las implementaciones entre sí.
Esta actividad se denomina experimentación y su esencia es obtener un modelo de aprendizaje automático funcional que pueda utilizarse para resolver tareas correspondientes en el futuro.
El bloque denominado “C” en el diagrama describe el proceso de realización de experimentos de aprendizaje automático.
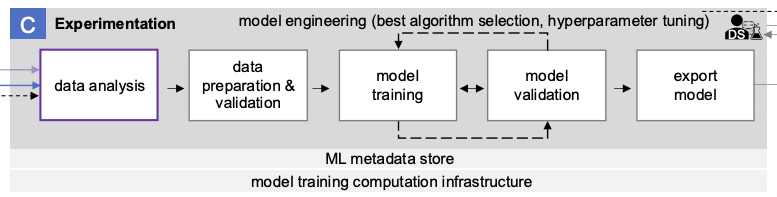
Incluye las siguientes etapas:
- Análisis de datos
- Preparación y validación de datos
- Entrenamiento de modelos
- Validación del modelo
- Exportación de modelos
Análisis de datos
Muchas decisiones en el desarrollo de ML se basan en el análisis de los datos disponibles en la empresa (no necesariamente big data). Es imposible entrenar un modelo con métricas de calidad objetivo sobre datos de baja calidad o datos que no existen. Por lo tanto, es importante entender qué datos tenemos y qué podemos hacer con ellos. Para ello, por ejemplo, podemos realizar una investigación ad-hoc utilizando Jupyter o Superset, o un Análisis de Datos Exploratorio estándar (AED).
Se puede lograr una mejor comprensión de los datos mediante el análisis semántico y estructural. Sin embargo, la preparación de los datos no siempre está dentro del ámbito de influencia del equipo del proyecto, lo que en tales casos está garantizado que surjan dificultades adicionales. A veces, en esta etapa, queda claro que no tiene sentido continuar con el desarrollo del proyecto porque los datos no son adecuados para el trabajo.

Optimización gratuita de costos de la nube y gestión mejorada de recursos ML/IA de por vida
Calidad de los datos de entrada
Una vez que se ha establecido la confianza en los datos disponibles, es necesario considerar las reglas para su preprocesamiento. Incluso si hay un gran conjunto de datos adecuados, no hay garantía de que no contenga valores faltantes, valores distorsionados, etc. Aquí es donde entran en juego el término “calidad de los datos de entrada” y la conocida frase “basura que entra, basura que sale”. No importa lo bueno que sea el modelo utilizado, arrojará malos resultados con datos de baja calidad. En la práctica, se gastan muchos recursos del proyecto en formar un conjunto de datos de alta calidad.
Entrenamiento y validación de modelos ML
Después de la etapa anterior, tiene sentido tener en cuenta las métricas del modelo entrenable a la hora de realizar experimentos. En el contexto del bloque considerado, el experimento consiste en entrenar y validar el modelo ML. De hecho, el experimento consiste en el esquema clásico de entrenar la versión deseada del modelo con la versión seleccionada. conjunto de hiperparámetros en el conjunto de datos preparado. Para ello, el propio conjunto de datos se divide en conjuntos de entrenamiento, prueba y validación. Se selecciona el conjunto óptimo de hiperparámetros para los dos primeros, mientras que la comprobación final se realiza en el conjunto de validación para confirmar que el modelo entrenado en el conjunto de hiperparámetros seleccionado se comporta adecuadamente en datos desconocidos que no participaron en el proceso de selección de hiperparámetros y entrenamiento. Este artículo Da más detalles sobre el proceso descrito.
Guardar código e hiperparámetros en el repositorio
El código del modelo y los parámetros seleccionados se guardan en el repositorio corporativo si las métricas del modelo de entrenamiento se consideran buenas.
El objetivo clave del proceso de experimentación es la ingeniería de modelos, lo que implica seleccionar el mejor algoritmo para implementar la tarea (selección del mejor algoritmo) y los mejores hiperparámetros del modelo (ajuste de hiperparámetros).
La complejidad de la realización de experimentos radica en que el desarrollador debe probar muchas combinaciones de parámetros del modelo. Y esto sin mencionar las diversas opciones para utilizar herramientas matemáticas. En general, esto no es fácil. Entonces, ¿qué se debe hacer si, durante las combinaciones de parámetros, no se pueden lograr las métricas deseadas?
💡 También te podría interesar nuestro artículo "¿Cuáles son los principales desafíos del proceso MLOps?"
Descubra los desafíos del proceso MLOps, como datos, modelos, infraestructura y personas/procesos, y explorar posibles soluciones para superarlos →
✔️ OptScale, una plataforma de código abierto FinOps y MLOps que ayuda a las empresas a optimizar los costos de la nube y brindar mayor transparencia en el uso de la nube, está completamente disponible en Apache 2.0 en GitHub →




