Please consider giving OptScale aStar on GitHub, it is 100% open source. It would increase its visibility to others and expedite product development. Thank you!
OptScale’s new AWS S3 Duplicate Object Finder: Merging FinOps and MLOps in one open source platform
In the ever-evolving world of open-source technology, OptScale continues to lead the way, seamlessly integrating FinOps and MLOps into one cohesive platform. Available as an open-source solution on GitHub and a SaaS version at my.optscale.com, OptScale is designed to meet the diverse needs of its growing user base. Today, we’re excited to unveil its latest innovation: the Duplicate Object Finder for AWS S3, a groundbreaking feature for organizations leveraging the AWS cloud ecosystem.
For those new to OptScale, here’s a brief overview. OptScale is an open-source platform that bridges financial operations (FinOps) and machine learning operations (MLOps). In simple terms, it helps businesses harness the potential of machine learning while keeping cloud costs under control.
Tackling the challenge of AWS S3 redundancy
As organizations expand their data storage needs, AWS S3 has become a go-to solution, offering unparalleled scalability, reliability, and availability. However, with vast storage capabilities comes an often-overlooked problem: duplicate objects. These redundant files quietly accumulate over time, driving up cloud storage costs and complicating data management.
The new Duplicate Object Finder feature directly addresses this challenge. It empowers businesses to identify and eliminate unnecessary duplicates in their S3 storage, reducing costs and enhancing the efficiency of cloud storage operations.
OptScale’s Duplicate Object Finder: A revolutionary tool for AWS S3
High-precision duplicate detection: Ensure accurate and efficient cleanup
Once integrated, OptScale performs a comprehensive scan of your AWS S3 environment, pinpointing duplicate objects. This meticulous approach ensures businesses can confidently address redundant data without fear of mistakenly deleting critical files.
OptScale Duplicate S3 Object Finder breaks free from the limitations of single-account tools. It enables users to connect an unlimited number of AWS cloud accounts. This feature is invaluable for enterprises managing multiple S3 buckets across various accounts, offering unparalleled flexibility and scalability.
Enhanced storage practices: Optimize S3 organization and performance
Beyond cost savings, the OptScale feature promotes better storage hygiene. Removing redundant data simplifies storage management, accelerates retrieval processes, and enhances analytics efficiency. By maintaining a clean and organized storage environment, businesses can improve overall operational workflows.
Duplicate objects in AWS S3 can lead to significant, often hidden, cloud storage costs. OptScale highlights these redundancies, providing businesses with actionable insights to reduce expenses. By eliminating unnecessary duplicates, companies can maximize their return on investment (ROI) for cloud storage while minimizing waste.
Free cloud cost optimization & enhanced ML/AI resource management for a lifetime
Experience OptScale: Harness open source capabilities or go SaaS for swift deployment
This powerful feature is available to the open-source community through OptScale’s GitHub repository. For those seeking a more streamlined experience, OptScale also offers a SaaS version at my.optscale.com. The SaaS option delivers the same robust functionality without requiring users to manage deployment, offering a quick and user-friendly way to leverage the full potential of this groundbreaking tool.
Step-by-step guide: Leveraging cutting-edge OptScale's Duplicate Object Finder
1. Choose OptScale’s open source or SaaS options
Decide how you want to use OptScale. You can either use the open-source version via the GitHub repository or the SaaS version at my.optscale.com. Both options provide full access to the Duplicate Object Finder feature, catering to different user preferences.
SaaS version
open source version
2. Integrate seamlessly
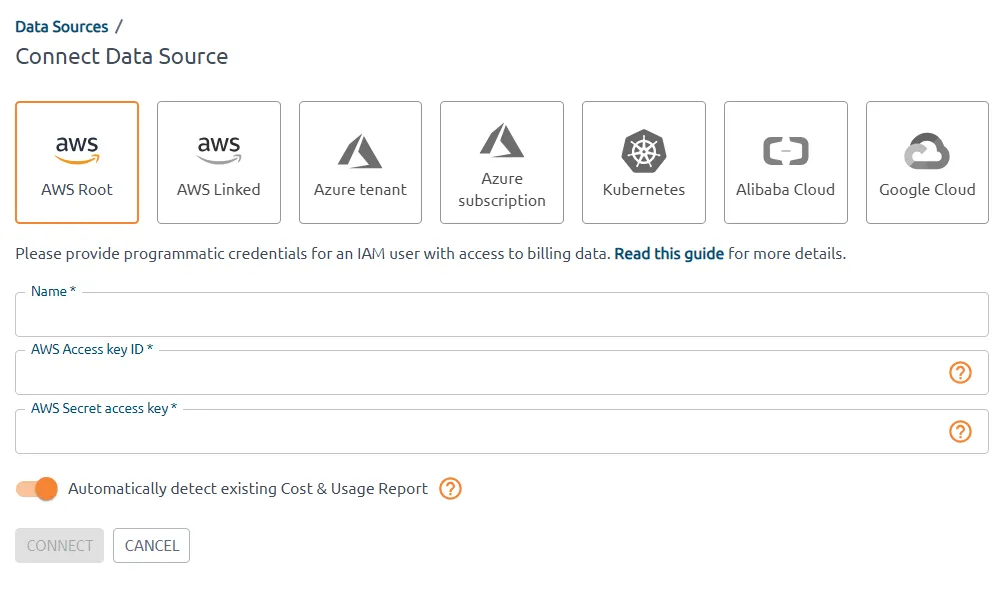
Follow OptScale’s step-by-step integration guidelines to connect your AWS accounts. The process’s user-friendly design ensures that setup will go smoothly and require little work.
AWS data source integration
3. Let the automated scan work for you
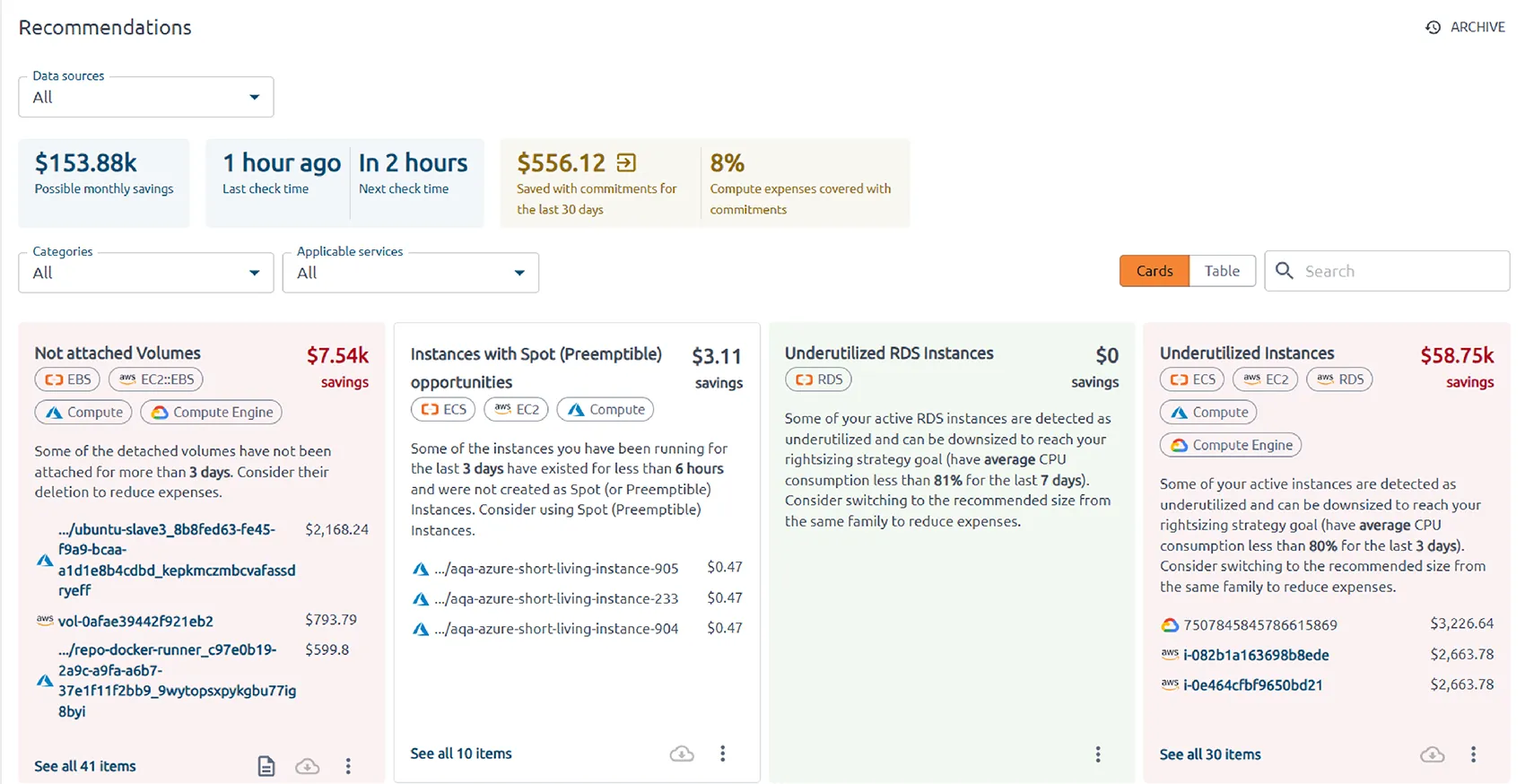
Once integrated, let OptScale handle the heavy lifting. The tool will thoroughly scan your AWS S3 buckets, identifying and cataloging duplicate objects with precision and efficiency.
Recommendation page
4. Act on insightful results
With a comprehensive list of duplicate objects at your fingertips, you have the flexibility to take informed actions. Whether you delete, archive, or further analyze the redundant data, the decision is entirely yours.
Summary
The digital landscape is saturated with tools claiming to optimize operations, but few tackle challenges as significant and pervasive as data redundancy in cloud storage. OptScale’s Duplicate Object Finder isn’t just a feature—it’s a transformative approach to AWS S3 management.
This tool promises immediate cost savings and promotes better storage practices, streamlined operations, and efficient data management. It’s an opportunity to rethink how businesses organize and utilize their data, enabling them to declutter and optimize confidently.
Experience the future of AWS S3 storage today with OptScale. Once you embrace this revolutionary feature, your cloud storage management will never be the same.
✔️ While there are multiple ways to achieve cloud cost visibility, OptScale, the FIRST open-source solution, helps companies fully understand and provide complete transparency to cloud spending.
A full description of OptScale as a FinOps and MLOps open source platform to optimize cloud workload performance and infrastructure cost. Cloud cost optimization, VM rightsizing, PaaS instrumentation, S3 duplicate finder,RI/SP usage, anomaly detection, + AI developer tools for optimal cloud utilization.