As principais partes do esquema, que descreve os principais processos de MLOps, são blocos horizontais, dentro dos quais os aspectos processuais de MLOps são descritos (eles são atribuídos às letras A, B, C, D). Cada um deles é projetado para resolver tarefas específicas dentro da estrutura de garantir a operação ininterrupta dos serviços de ML da empresa. Para entender melhor o esquema, seria bom começar com Experimentação.
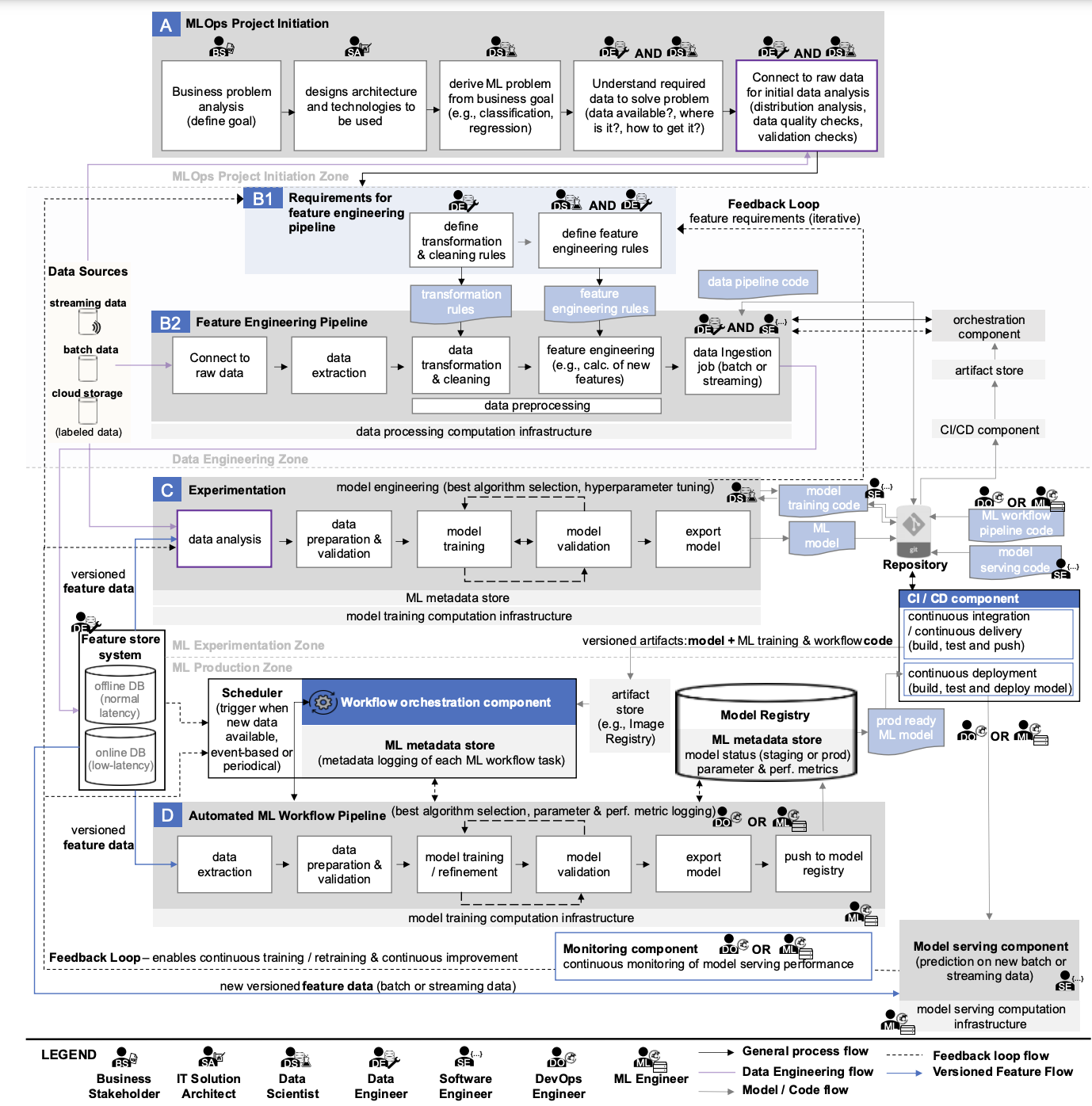
Experimentação, ou o processo de condução de experimentos
Se uma empresa tem serviços de ML, então há funcionários trabalhando no Jupyter. Em muitas empresas, todos os processos de desenvolvimento de ML são concentrados nessa ferramenta. É aqui que a maioria das tarefas começa, para as quais é necessário implementar práticas de MLOps.
Por exemplo, a Empresa A tem a necessidade de automatizar parte de um processo usando machine learning (digamos que o departamento e os especialistas relevantes estejam disponíveis). É improvável que a solução para a tarefa seja conhecida com antecedência. Portanto, os desenvolvedores precisam estudar a tarefa e testar possíveis maneiras de implementá-la.
Para esse propósito, um engenheiro/desenvolvedor de ML escreve código para várias implementações de tarefas e avalia os resultados obtidos em relação aos métricas de destino. Isso quase sempre é feito no Jupyter Lab. Nesse formato, muitas informações importantes precisam ser registradas manualmente, e então as implementações precisam ser comparadas entre si.
Essa atividade é chamada de experimentação. Sua essência é obter um modelo de ML funcional que pode ser usado para resolver tarefas correspondentes no futuro.
O bloco denominado “C” no diagrama descreve o processo de condução de experimentos de ML.
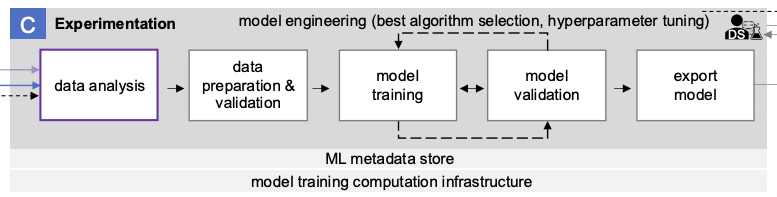
Inclui as seguintes etapas:
- Análise de dados
- Preparação e validação de dados
- Treinamento de modelo
- Validação do modelo
- Exportação de modelo
Análise de dados
Muitas decisões no desenvolvimento de ML são baseadas na análise dos dados disponíveis na empresa (não necessariamente big data). É impossível treinar um modelo com métricas de qualidade alvo em dados de baixa qualidade ou dados que não existem. Portanto, é importante entender quais dados temos e o que podemos fazer com eles. Para fazer isso, por exemplo, podemos conduzir uma investigação ad-hoc usando Jupyter ou Superset, ou uma Análise de Dados Exploratória padrão (EDA).
Uma melhor compreensão dos dados pode ser obtida em conjunto com a análise semântica e estrutural. No entanto, a preparação dos dados nem sempre está dentro da esfera de influência da equipe do projeto – em tais casos, dificuldades adicionais são garantidas. Às vezes, neste estágio, fica claro que não faz sentido continuar desenvolvendo o projeto porque os dados são inadequados para o trabalho.

Otimização gratuita de custos de nuvem e gerenciamento aprimorado de recursos de ML/IA para toda a vida
Qualidade dos dados de entrada
Uma vez estabelecida a confiança nos dados disponíveis, é necessário considerar as regras para seu pré-processamento. Mesmo que haja um grande conjunto de dados adequados, não há garantia de que ele não contenha valores ausentes, valores distorcidos, etc. É aqui que o termo “qualidade dos dados de entrada” e a conhecida frase “Lixo entra – lixo sai” entram em cena. Não importa quão bom seja o modelo usado, ele dará resultados baixos em dados de baixa qualidade. Na prática, muitos recursos do projeto são gastos na formação de um conjunto de dados de alta qualidade.
Treinamento e validação do modelo ML
Após a etapa anterior, faz sentido levar em conta as métricas do modelo treinável ao conduzir experimentos. No contexto do bloco considerado, o experimento consiste em treinar e validar o modelo de ML. Na verdade, o experimento consiste no esquema clássico de treinar a versão desejada do modelo com o selecionado conjunto de hiperparâmetros no conjunto de dados preparado. Para fazer isso, o próprio conjunto de dados é dividido em conjuntos de treinamento, teste e validação. O conjunto ótimo de hiperparâmetros é selecionado para os dois primeiros, enquanto a verificação final é realizada no conjunto de validação para confirmar que o modelo treinado no conjunto selecionado de hiperparâmetros se comporta adequadamente em dados desconhecidos que não participaram do processo de seleção de hiperparâmetros e treinamento. Este artigo fornece mais detalhes sobre o processo descrito.
Salvando código e hiperparâmetros no repositório
O código do modelo e os parâmetros selecionados são salvos no repositório corporativo se as métricas do modelo de treinamento forem consideradas boas.
O objetivo principal do processo de experimentação é a engenharia de modelos, o que implica selecionar o melhor algoritmo para implementar a tarefa (seleção do melhor algoritmo) e os melhores hiperparâmetros do modelo (ajuste de hiperparâmetros).
A complexidade de conduzir experimentos é que o desenvolvedor precisa testar muitas combinações de parâmetros do modelo. E isso sem mencionar as várias opções para usar ferramentas matemáticas. Em geral, isso não é fácil. Então, o que você deve fazer se, durante as combinações de parâmetros, as métricas desejadas não puderem ser alcançadas?
💡 Você também pode se interessar pelo nosso artigo 'Quais são os principais desafios do processo de MLOps?'
Descubra os desafios do processo MLOps, como dados, modelos, infraestrutura e pessoas/processos, e explorar soluções potenciais para superá-los →
✔️ OptScale, uma plataforma de código aberto FinOps e MLOps, que ajuda as empresas a otimizar os custos da nuvem e trazer mais transparência ao uso da nuvem, está totalmente disponível em Apache 2.0 no GitHub →




