Li recentemente um bom artigo pela equipe de engenharia da Intuit, onde eles mencionaram um tópico interessante — bolha dupla. Em termos de nuvens, é um estado durante migração para nuvem ou transformação digital quando você paga por ambas as nuvens, sites de origem e de destino. Vamos discutir o quão comum isso é.
Um projeto padrão de migração para a nuvem consiste em um conjunto definido de etapas:
1. Justificativa de TI e comprovação de uma necessidade comercial. A justificativa pode ser evitar o bloqueio de fornecedor, ciclo de renovação de licença de hardware ou software de arrendamento de datacenter, velocidade de dimensionamento, TCO ou desconto de nuvem pública etc. Normalmente, quando há uma justificativa clara, não é um problema comprovar a necessidade comercial.
2. Definição do escopo do projeto. Nesta etapa, uma pessoa responsável (gerente de projeto) e aplicações/recursos específicos são definidos.
3. Fase de migração para a nuvem.
4. Post-mortem.
Falaremos apenas sobre p. 2 e 3 por enquanto. É normal que durante o processo de migração haja momentos em que você tenha recursos em execução em ambas as nuvens, de origem e de destino. Alguns dos recursos podem já ter sido migrados, alguns ainda podem estar em uma fila ou mesmo não definidos para migração e ainda em execução em uma nuvem de origem. Mas há um caso interessante quando você migra alguns recursos (em alguns casos, centenas ou milhares de máquinas) e precisa pagar por eles duas vezes.
Alcançar a eficácia gestão de custos é tudo sobre otimização e rastreamento. Com um conjunto de políticas, princípios e processos em vigor, as empresas podem apaziguar as partes interessadas e garantir que seus gastos com a nuvem permaneçam sob controle. Se sua conta de gastos com a nuvem for uma surpresa toda vez que você a receber, você simplesmente não está aproveitando todas as ferramentas de governança de custos disponíveis.
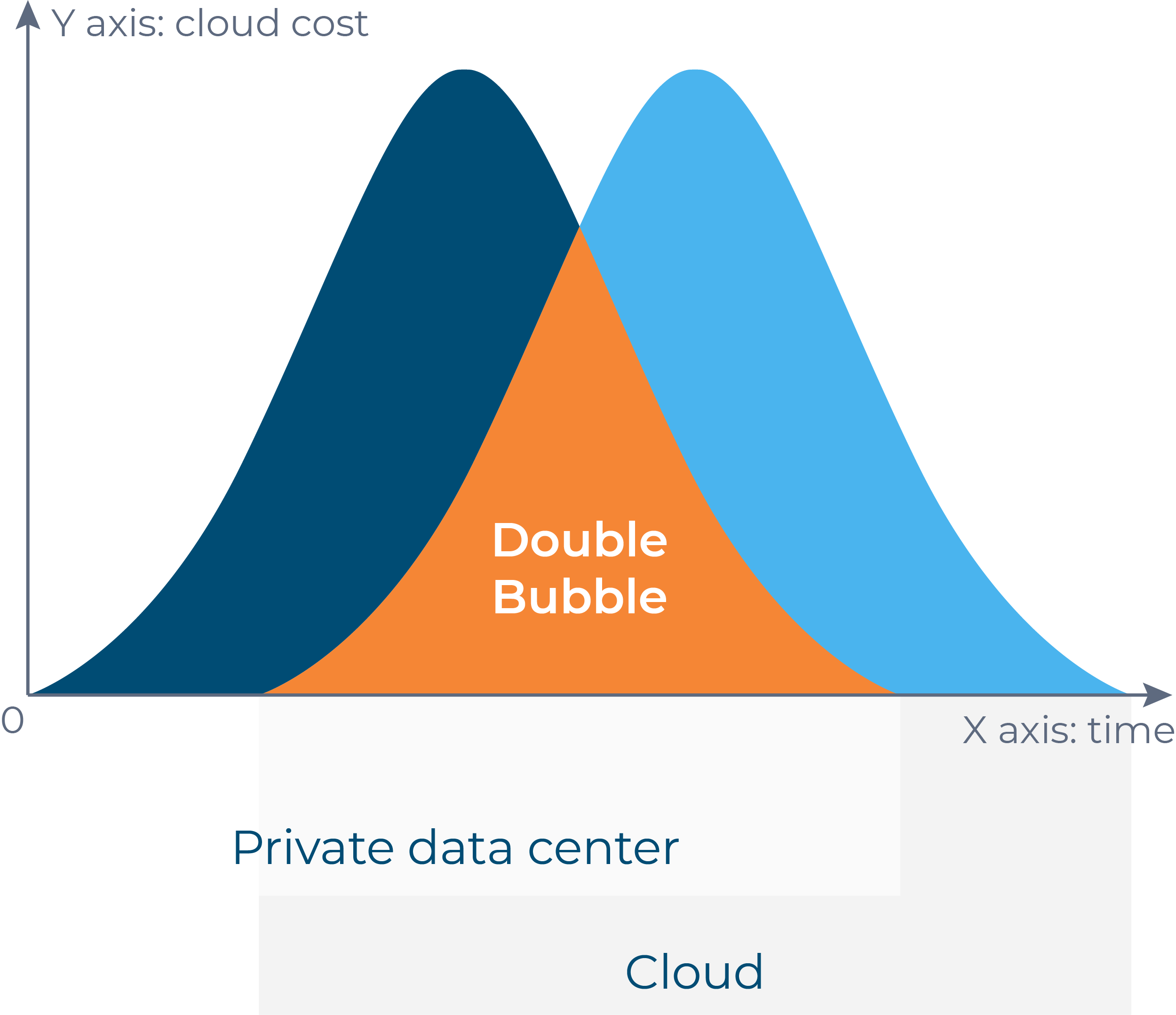
Quando as empresas definem o que migrar para a nuvem, geralmente pensam em categorias como aplicativos, departamentos ou recursos inteiros. Consultores ou fornecedores experientes em migração sempre recomendam dividir os recursos em blocos de 30 a 50 VMs e migrar por fases. Isso reduz o risco de um lado e, do outro, ajuda a eliminar a bolha. Idealmente, um único aplicativo deve estar em um bloco. Nesse caso, você pode migrar e testar toda a parte granular do seu sistema e evitar problemas de localidade de dados. Lembre-se de que o tráfego entre regiões e o tráfego de saída para a nuvem não são gratuitos e são bastante caros. É melhor pensar nisso antes de receber sua primeira fatura da nuvem 🙂
A causa raiz da bolha está no escopo "replicação -> teste" -> transição. Quando você migra um bloco, leva algum tempo para replicar os dados, definir como você obterá incrementos (melhor de forma automatizada), testar o bloco em uma nuvem de destino e agendar uma janela de manutenção para executar a transição. E essas 3 fases formam a bolha. Você armazena os dados em dispositivos de bloco ou armazenamento de objetos, executa VMs em uma nuvem de destino e paga pela computação. Na maioria dos casos, as migrações de teste podem durar de 1 a 3 semanas (pode ser até mais) até que uma equipe proprietária do aplicativo migrado valide que tudo está bem com ele em uma nuvem de destino e que não há degradação de desempenho ou outros problemas. E se você migrar vários blocos em paralelo, a bolha aumentará.
Então, como evitar a bolha…
1. Antes de tudo, identifique seu ritmo de migração. Seja muito franco consigo mesmo. É exatamente assim que se aprende uma nova habilidade — bem devagar no começo e muito melhor depois de algumas iterações.
2. Defina uma fila de aplicações/blocos. Coloque-a no calendário do seu projeto de migração.
3. Descubra uma maneira de replicar VMs sem tempo de inatividade e sem precisar replicá-las constantemente. Dezenas de ferramentas fazem isso, economizando tempo e dinheiro, já que você paga menos pelo armazenamento.
4. Comunique-se com as equipes responsáveis pelos blocos ou aplicativos. Defina os critérios de aceitação e o processo de transição com elas. Quanto mais cedo começarem a pensar nisso, mais preparados estarão quando chegar a hora. Defina os intervalos de tempo para testar a migração. Esta é a etapa mais importante, pois os testes estouram a bolha e, geralmente, as equipes não têm ideia de como testar os aplicativos, quais são os componentes ou quem é o proprietário de cada máquina.
5. Defina o período de espera — quanto tempo você espera até remover as VMs migradas do ambiente de origem. Não se esqueça de que você precisa de um plano B caso algo dê errado com as VMs e os aplicativos em uma nuvem de destino e você ainda pague (direta ou indiretamente) pelas máquinas no lado de origem.
6. Encerre os testes assim que perceber que a equipe não está preparada ou que não é a prioridade adequada. Se não estiverem motivados, perderão tempo (equivalente a dinheiro em nuvens públicas) ou, pior ainda, tomarão uma decisão (aceitar ou rejeitar) com base em critérios estranhos e continuarão usando as máquinas em uma nuvem de origem ou descobrirão que houve problemas quando as VMs de origem já teriam sido removidas. Reforce a conversa com o gerente ou a alta gerência para ajustar as prioridades de ambas as equipes.
7. Se os testes forem aprovados, prossiga com a transição. Remova todos os snapshots e teste as migrações dos aplicativos migrados. Lembre-se de iniciar a contagem regressiva para o tempo de espera.
8. Revise suas estimativas de ritmo e ajuste sua programação.
Você terá algum tipo de bolha dupla em qualquer migração projeto, mas você pode controlar o tamanho dele por meio de planejamento e comunicação adequados com os proprietários de aplicativos e VMs. Somente pessoas corajosas migram toda a infraestrutura de uma só vez; pessoas inteligentes planejam e fazem isso em partes e fases.