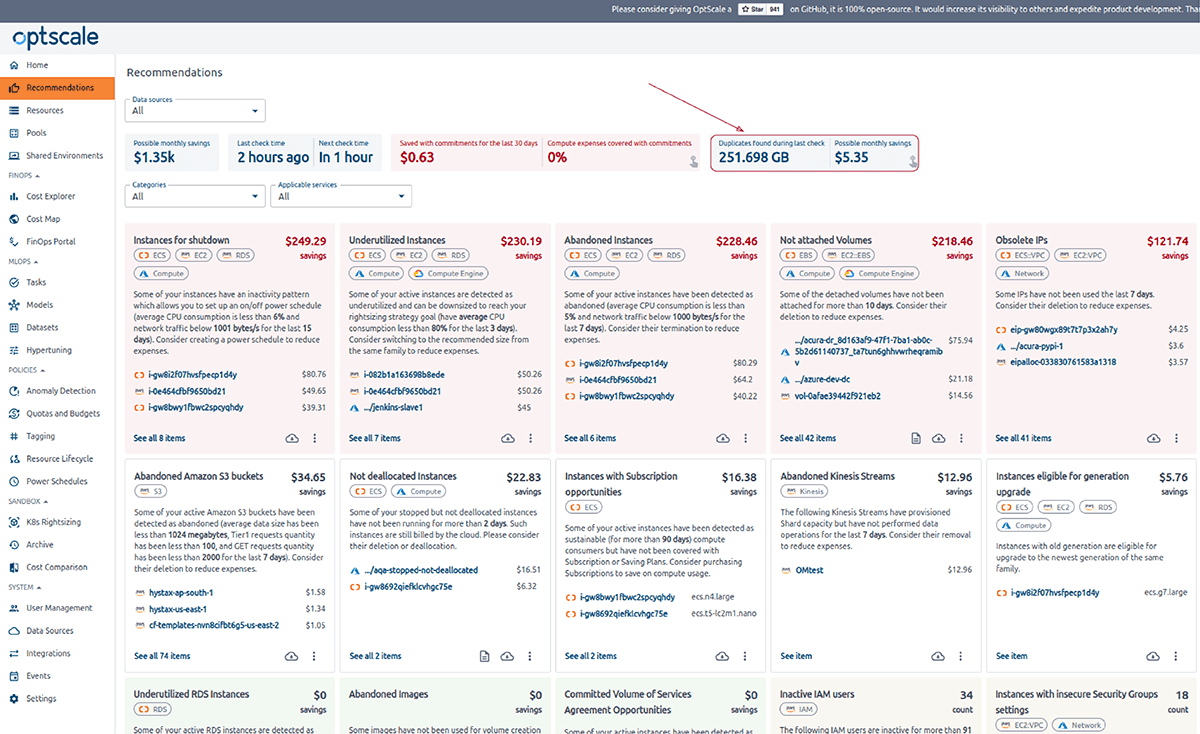
No Amazon S3 (Simple Storage Service), objetos duplicados se referem a arquivos ou objetos dentro de um ou vários buckets com conteúdo idêntico. Essas duplicatas podem ocorrer por vários motivos, como uploads acidentais, vários uploads do mesmo arquivo ou processos de sincronização.
É importante observar que objetos duplicados podem aumentar custos de armazenamento já que cada objeto é cobrado separadamente com base no tamanho e na duração do armazenamento. Portanto, é geralmente recomendado que objetos duplicados sejam gerenciados de forma eficiente, evitando-os por meio de convenções de nomenclatura adequadas ou usando versionamento quando necessário.
Objetos duplicados no AWS S3 podem apresentar vários desafios e problemas potenciais. Objetos duplicados consomem espaço de armazenamento adicional, levando a custos de armazenamento mais altos. Manter o controle de várias cópias dos mesmos dados pode se tornar desafiador, especialmente em ambientes com uploads e atualizações de dados frequentes. Muitos objetos duplicados em um bucket do S3 podem afetar o desempenho, especialmente ao listar, acessar ou gerenciar objetos. Isso pode resultar em tempos de resposta mais lentos e maior latência para operações de bucket. Objetos duplicados podem levantar preocupações de conformidade e governança, especialmente em setores regulamentados onde a duplicação de dados pode levar a problemas com políticas de retenção de dados, regulamentações de privacidade de dados e requisitos de auditoria.
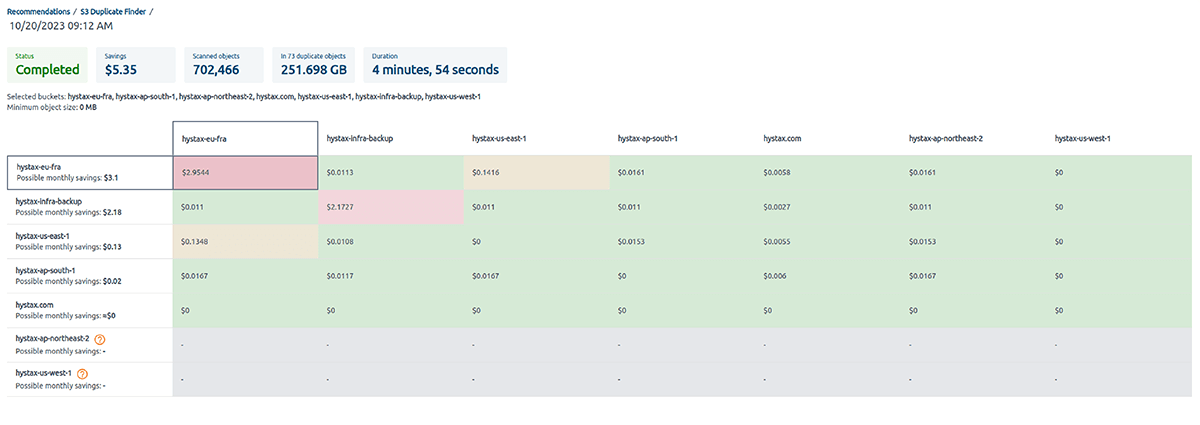
O OptScale pode ajudar a mitigar esses problemas. É essencial auditar os buckets do S3 para objetos duplicados regularmente. Além disso, a ferramenta pode ajudar a identificar e lidar com objetos duplicados proativamente.
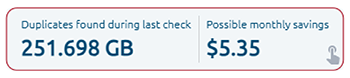
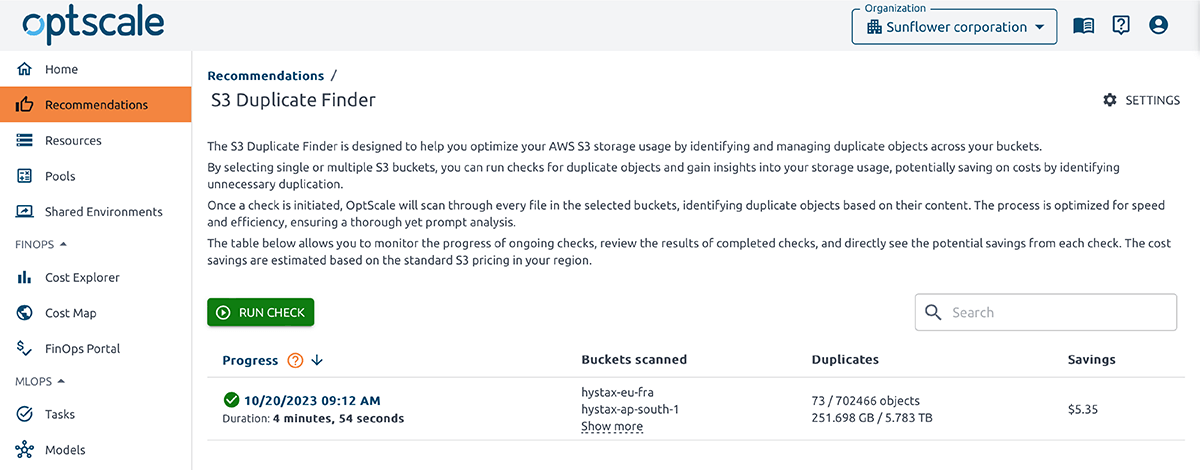
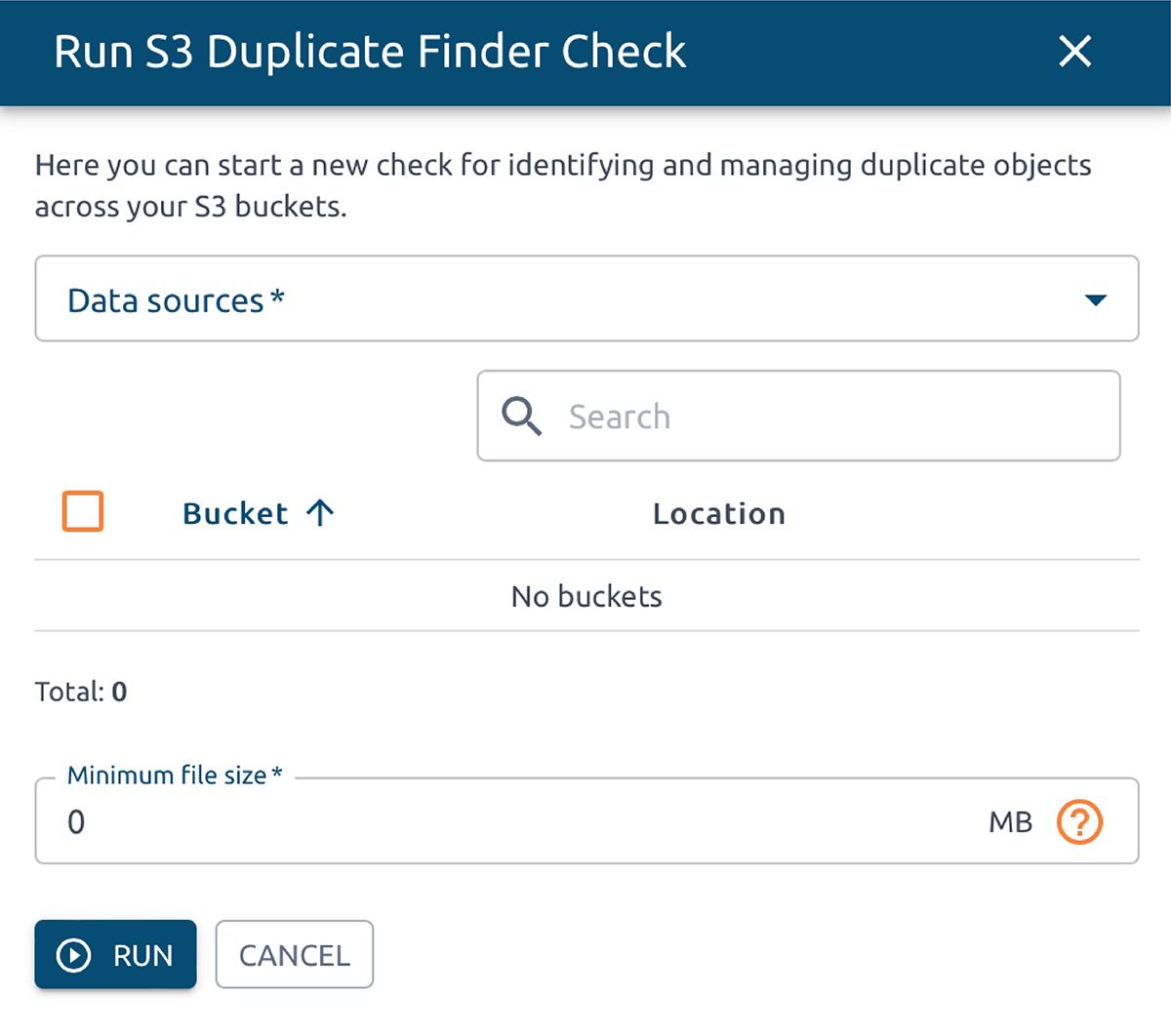
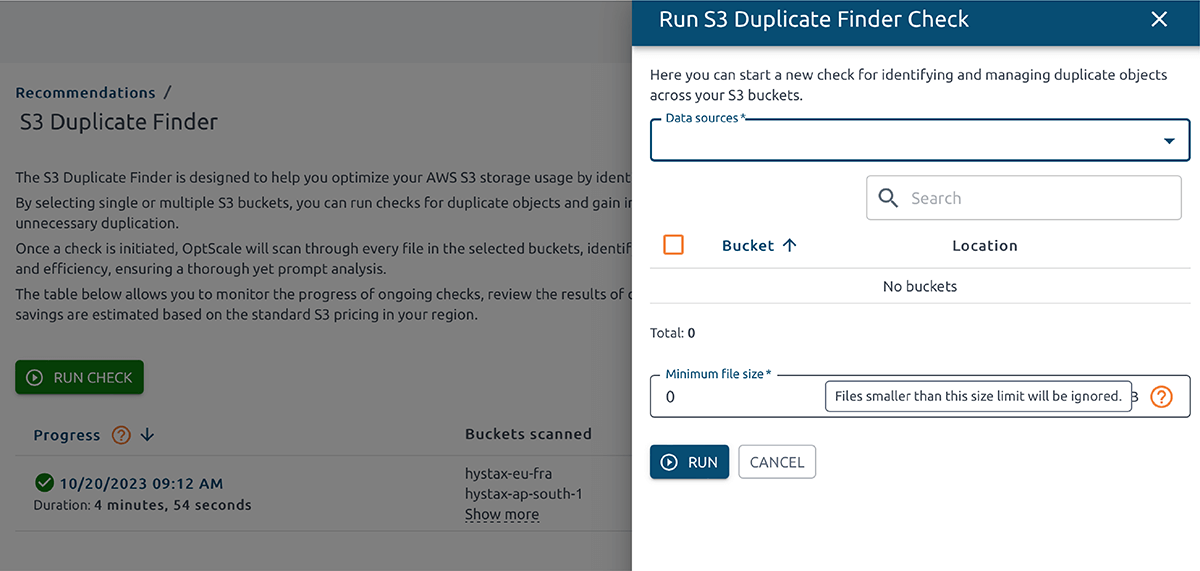
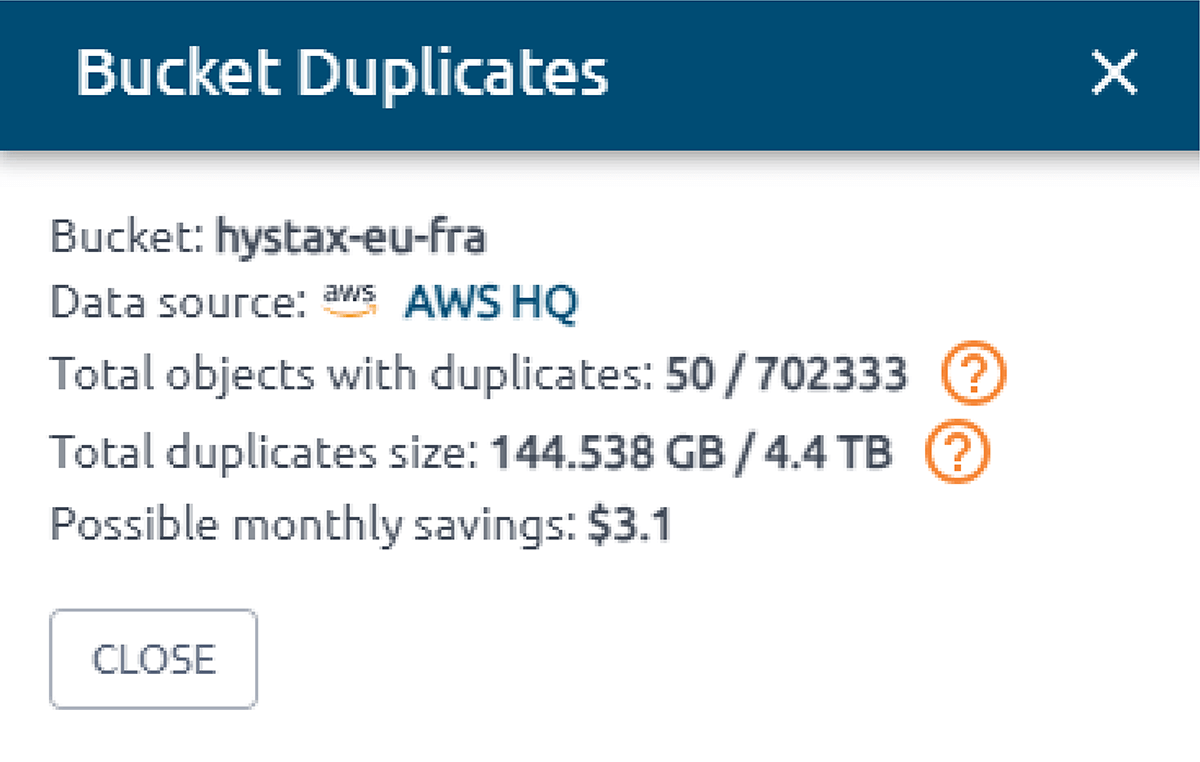
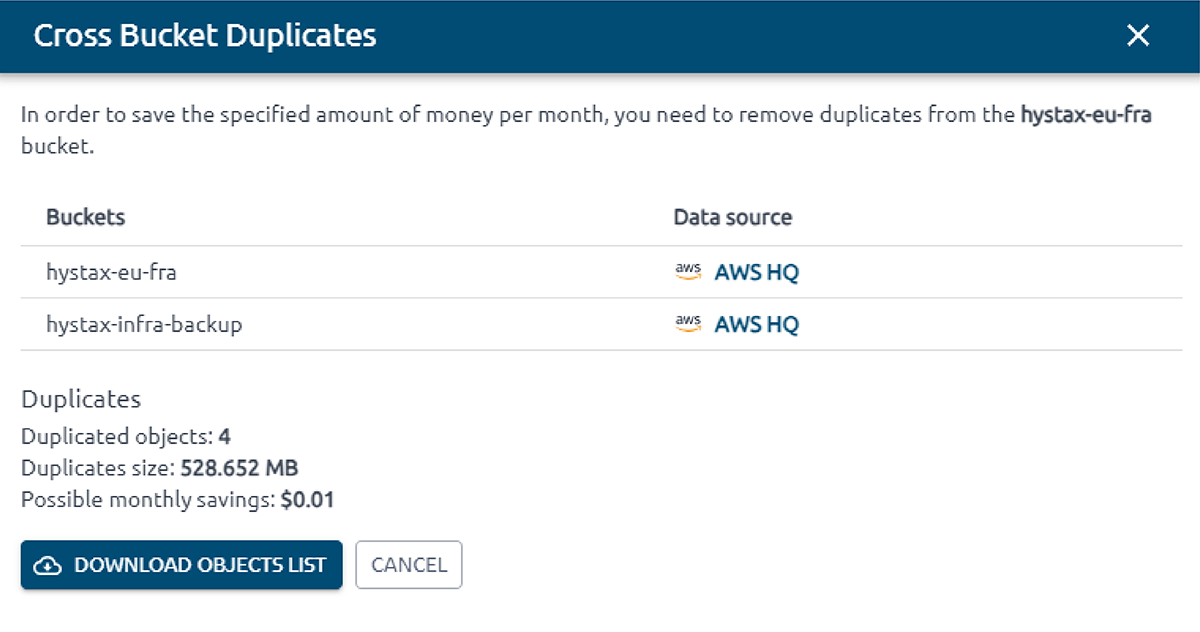
O OptScale permite encontrar objetos duplicados no AWS S3. O S3 Duplicate Finder (como é chamado no produto) foi projetado para ajudar você a otimizar seu uso de armazenamento no AWS S3 identificando e gerenciando objetos duplicados em seus buckets.
Selecionar um ou vários buckets S3 permite que você execute verificações de objetos duplicados e obtenha insights sobre seu uso de armazenamento. Ao identificar duplicações desnecessárias, você pode economizar em custos.
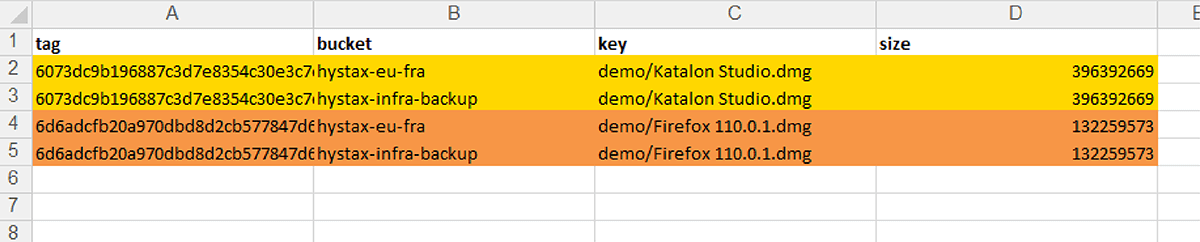
Uma vez que uma verificação é iniciada, o OptScale escaneará todos os arquivos nos buckets selecionados, identificando objetos duplicados com base em seu conteúdo. O processo é otimizado para velocidade e eficiência, garantindo uma análise completa, mas rápida.