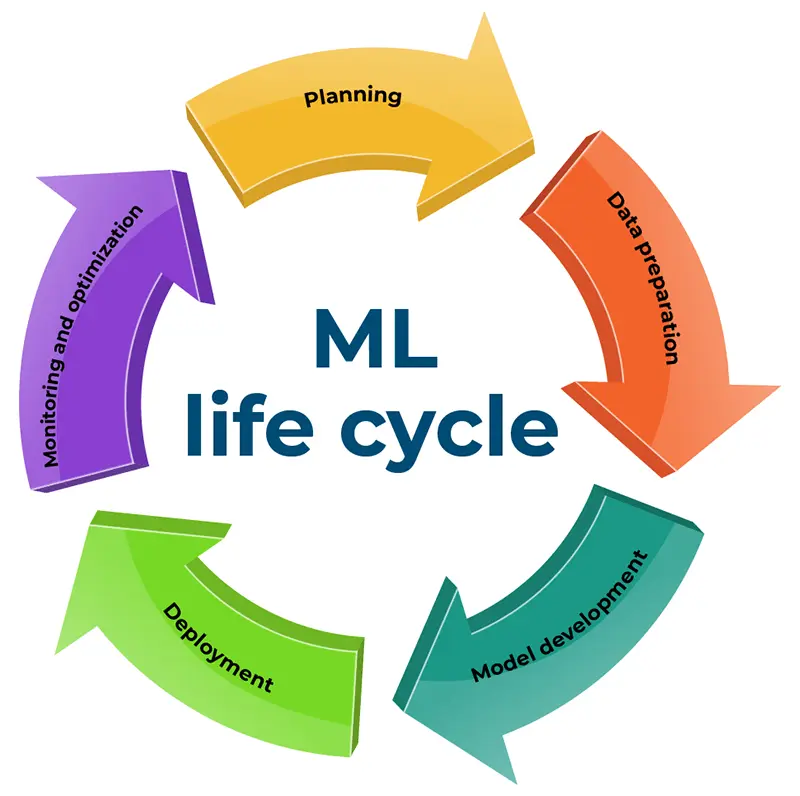
Emprender la construcción y el uso de un modelo de aprendizaje automático (ML) es una tarea llena de matices que exige una planificación meticulosa y un esfuerzo dedicado. Este intrincado proceso se desarrolla a lo largo de cinco etapas fundamentales dentro del ciclo de vida del aprendizaje automático, cada una con consideraciones críticas. Una comprensión integral de este ciclo de vida permite a los científicos de datos asignar recursos y obtener información inmediata sobre su progreso de manera adecuada. Dentro de los límites de este artículo, profundizamos en las etapas por excelencia (que abarcan la planificación, la preparación de datos, la construcción del modelo, la implementación y la supervisión), ofreciendo una exploración detallada de su importancia en el aprendizaje automático.
La importancia de un marco en el ciclo de vida del aprendizaje automático
El ciclo de vida del aprendizaje automático organiza la integración estratégica de la inteligencia artificial y el aprendizaje automático, y traza un curso desde la concepción del proyecto hasta el desarrollo del modelo y los momentos críticos de monitoreo y optimización. Más allá de la narrativa habitual, este recorrido dinámico se desarrolla con el objetivo único de abordar problemas específicos mediante la implementación de un modelo de aprendizaje automático. Sin embargo, alejándose de las perspectivas convencionales, subraya la necesidad persistente de vigilancia posterior a la implementación, haciendo hincapié en la optimización y el mantenimiento continuos como salvaguardas indispensables contra la degradación del modelo y la insidiosa invasión del sesgo.

Optimización gratuita de costos de la nube y gestión mejorada de recursos ML/IA de por vida
Fases del desarrollo del aprendizaje automático
Para emprender el viaje del desarrollo del aprendizaje automático es necesario explorar en profundidad su ciclo de vida lleno de matices, compuesto por cinco etapas fundamentales.
Planificación pionera
En el origen de cada expedición de desarrollo de modelos se encuentra una fase crucial de planificación. Esta etapa implica desentrañar meticulosamente los problemas identificados con una mirada perspicaz sobre la eficiencia de los recursos. La hoja de ruta hacia el éxito comprende lo siguiente:
En la fase inicial del desarrollo del aprendizaje automático, la precisión es primordial para definir el problema específico, ya sea para abordar una tasa de conversión de clientes lenta o un aumento en las actividades fraudulentas. Posteriormente, el proceso exige la articulación de objetivos claros, que describan los resultados deseados, como aumentar las tasas de conversión de clientes o acabar con el comportamiento fraudulento. Se aplican métricas cuidadosamente establecidas para medir el éxito, y una tasa de precisión de 70% se considera encomiable, mientras que lograr una tasa entre 70% y 90% se considera el epítome del éxito. Este enfoque reflexivo y sistemático de la planificación establece las bases para un desarrollo exitoso del modelo de aprendizaje automático.
Preparación de datos
La segunda etapa del desarrollo del aprendizaje automático se centra en la adquisición y el refinamiento meticulosos de los datos. Dada la probabilidad de trabajar con un volumen sustancial de datos, es imperativo garantizar su precisión y relevancia antes de iniciar el proceso de creación de modelos.
Esta etapa fundamental de preparación de datos se desarrolla a través de varios pasos integrales. Inicialmente, la adquisición de un conjunto de datos sustancial se considera intensiva en recursos en la recopilación y etiquetado de datos, lo que impulsa la exploración de la viabilidad de los datos existentes. Se enfatiza la integración de datos de diversas fuentes y la alternativa de recopilación de datos a través de encuestas, entrevistas u observaciones. A continuación, se etiquetan los datos, asignando etiquetas distintas a los datos sin procesar, como imágenes, videos o texto, lo que ayuda a la categorización y la referencia futura. Posteriormente, la limpieza de datos se vuelve primordial, y el tamaño del conjunto de datos se correlaciona con la profundidad de la limpieza requerida. Se destaca la eliminación prudente de valores faltantes e información irrelevante antes de la construcción del modelo para mejorar la precisión y reducir los errores y el sesgo. La culminación implica el análisis exploratorio de datos (EDA), un paso fundamental que precede a la construcción del modelo, que examina el conjunto de datos a través de visualizaciones para obtener una descripción general resumida, ofrece información valiosa sobre los patrones predominantes y fomenta una comprensión matizada entre los científicos de datos.
Desarrollo de modelos
Con los datos preparados en la mano, el foco se desplaza a desarrollo de modelos, una fase fundamental en el ciclo de vida del aprendizaje automático, que abarca tres subpuntos clave:
- Selección y evaluación de modelos: el paso fundamental es elegir el tipo de modelo. Los científicos de datos ajustan y prueban varios modelos para identificar el que supera al resto. La selección suele basarse en la naturaleza de los datos y se opta por un modelo de clasificación o regresión con la mayor tasa de precisión.
- Entrenamiento del modelo: en la fase de experimentación, los científicos de datos introducen datos en el algoritmo elegido para extraer los resultados iniciales. Esta fase revela los primeros atisbos de la producción final, lo que proporciona información que orienta las modificaciones para mejorar las predicciones.
- Evaluación del modelo: una vez finalizada la fase de entrenamiento, la etapa final implica una revisión exhaustiva, en la que se examinan métricas como la exactitud y la precisión para medir el rendimiento del modelo. Esta evaluación se extiende a un análisis detallado de errores y sesgos, lo que permite a los analistas idear soluciones para eliminarlos. Si es necesario, los científicos de datos refinan y vuelven a ejecutar el modelo de forma iterativa, incorporando mejoras para aumentar la precisión y el rendimiento general.
Despliegue
La fase de implementación integra el modelo desarrollado en un entorno de producción existente, lo que permite tomar decisiones comerciales informadas. La etapa de implementación del modelo es una de las etapas más desafiantes dentro del ciclo de vida del aprendizaje automático; la implementación del modelo a menudo debe abordarse debido a la disparidad entre los lenguajes de creación de modelos tradicionales y los sistemas de TI de muchas organizaciones. En consecuencia, los científicos de datos con frecuencia se encuentran recodificando modelos para alinearlos con los sistemas de producción, lo que requiere un esfuerzo colaborativo entre los científicos de datos y los equipos de desarrollo (DevOps).
Monitoreo y optimización
En las etapas culminantes, los controles de mantenimiento continuos y las optimizaciones periódicas son imprescindibles. Como los modelos pueden degradarse con el tiempo, garantizar su precisión sostenida exige un control constante. escucha y optimización. Los esfuerzos de colaboración entre los científicos de datos y la mayoría de los ingenieros de software suelen ser fundamentales, ya que utilizan software de análisis predictivo para identificar y corregir problemas como la desviación o el sesgo del modelo. El análisis predictivo, que aprovecha los datos para discernir las tendencias de la industria y las mejores prácticas, es vital para pronosticar la pérdida de clientes o adaptar las campañas de marketing para captar el interés potencial.
Resumiendo
En conclusión, el ciclo de vida del aprendizaje automático se erige como un marco fundamental, que ofrece a los científicos de datos una vía estructurada para profundizar en las complejidades del desarrollo de modelos de aprendizaje automático. Guiada por este marco integral, la gestión del ciclo de vida del modelo de ML abarca un recorrido holístico, que comienza con la definición meticulosa de los problemas y culmina con la optimización continua del modelo. Como piedra angular para la competencia en aprendizaje automático, este marco de ciclo de vida encapsula la esencia del desarrollo de modelos estratégicos e informados, lo que facilita un enfoque sólido para resolver problemas complejos y avanzar en el campo de la inteligencia artificial.
Escala óptica, una plataforma MLOps y FinOps de código abierto en GitHub, ofrece transparencia y optimización completas de los gastos en la nube en varias organizaciones y cuenta con herramientas MLOps como ajuste de hiperparámetros, experimentos de seguimiento, modelos de versiones y tablas de clasificación de ML →



