In this article, we describe block D, devoted to the automated machine learning workflow.
Please, find the whole scheme, which describes key MLOps processes here. The main parts of the scheme are horizontal blocks, inside of which the procedural aspects of MLOps are described (they are assigned letters A, B, C, D). Each of them is designed to solve specific tasks within the framework of ensuring the uninterrupted operation of the company’s ML services.

From the beginning, we would like to mention that in this article, by ML system, we mean an information system that contains one or more components with a trained model that performs some part of the overall business logic. The better the ML model developed, the greater the impact of its operation. The trained model processes an incoming stream of requests and provides some predictions in response, automating some parts of the analysis or decision-making process.
The process of using the model to generate predictions is called inference, and the process of training the model is called training. A clear explanation of the difference between them can be borrowed from Gartner – here we’ll use cats as an example.
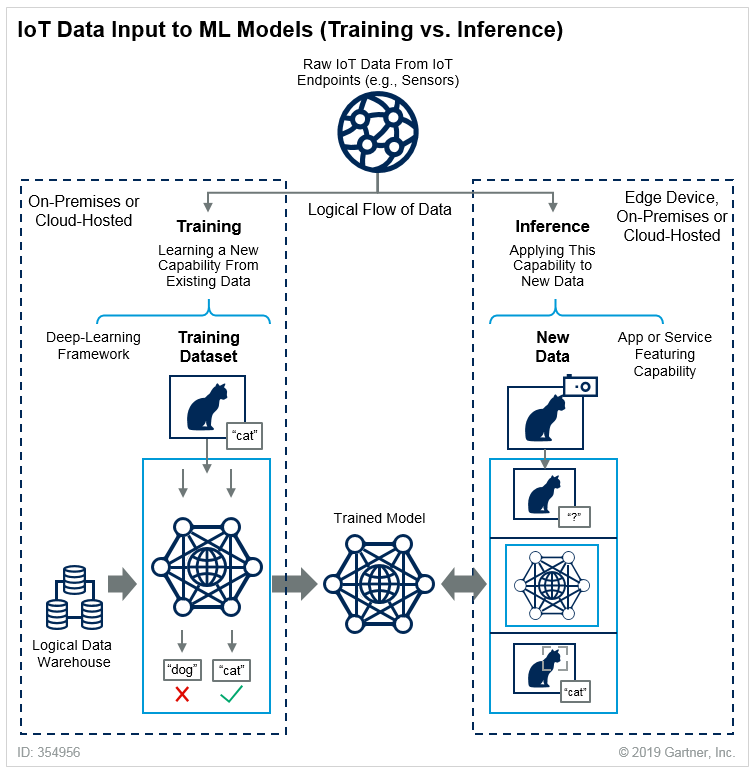
For the effective operation of a production ML system, it is important to monitor the inference metrics of the model. As soon as they begin to decline, the model needs to be retrained or replaced with a new one. This often happens due to changes in input data (data drift). For example, there is a business task where the model can recognize bread in photos, but it is given a photo of a corgi instead. The dogs in the example are for balance:

The model in the initial dataset knew nothing about corgis, so it predicts incorrectly. Therefore, the dataset needs to be changed, and new experiments need to be conducted. At the same time, the new model should be put into production as soon as possible. Users are not prohibited from uploading images of corgis, and they will get an erroneous result.
Now, let’s look at more real-life examples: let’s consider the recommendation system of a marketplace. Based on a user’s purchase history, purchases of similar users, and other parameters, a model or ensemble of models generates a block with recommendations. It includes products whose purchase revenue is regularly calculated and tracked.
Something happens, and the needs of buyers change. Therefore, the recommendations for them become outdated, and demand for the recommended products decreases. All this leads to a decrease in revenue.
Next, come the cries of managers and demands to restore everything by tomorrow, which lead to nothing. Why? There is not enough data about the new preferences of buyers, so you can’t even create a new model. Of course, you can take some basic recommendation generation algorithms (item-based collaborative filtering) and add them to production. This way, recommendations will work somehow, but it’s only a temporary “band-aid.”
Ideally, the process should be set up so that, based on metrics and without the guidance of managers, the process of retraining or experimenting with different models is launched. And the best one eventually replaces the current one in production. In the diagram, this is the Automated ML Workflow Pipeline (block D), which is triggered in some orchestration tool.
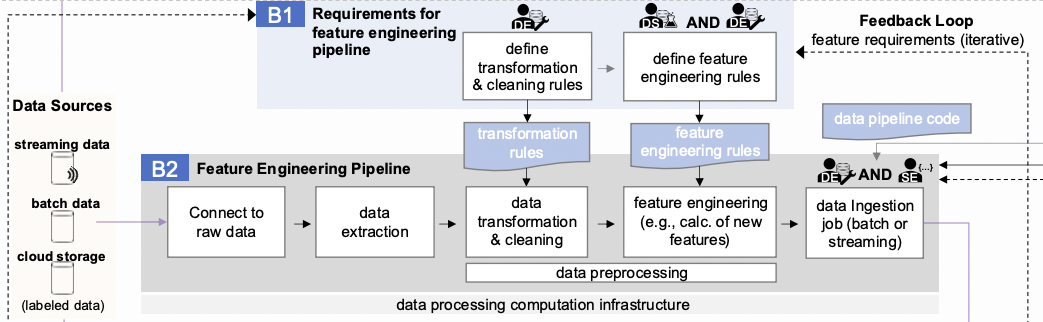

This is probably the most heavily loaded section of the scheme. The operation of Block D involves several key external components:
- the workflow orchestrator component is responsible for launching the pipeline on a specified schedule or event
- the feature store provides data on the features required for the model.
- the model registry and ML metadata store, where models and their metrics obtained after the completion of the launched pipeline are placed.
The structure of the block essentially combines the stages of experimentation (C) and feature development (B2). This is not surprising, given that these processes need to be automated. The main differences are in the last two stages:
- export model
- push to the model registry
The other stages are identical to those described above.
It is worth noting separately the service artifacts required by the orchestrator to launch the model retraining pipelines. In fact, this is code that is stored in a repository and runs on dedicated servers. It is versioned and modernized according to all the rules of software development. It is this code that implements the model retraining pipeline, and the result depends on its correctness.
It is worth noting that automating experiments in general is impossible. Of course, you can add the concept of AutoML to the process, but to date, there is no recognized solution that could be used with the same results for any experiment topic.
In general, AutoML works as follows:
- It somehow forms a set of combinations of model operating parameters.
- It launches an experiment for each resulting combination.
- It records the metrics for each experiment, based on which the best model is selected.
In essence, AutoML performs all the manipulations that a hypothetical Junior/Middle Data Scientist would perform in a circle of more or less standard tasks.
We’ve covered automation a bit. Next, it is necessary to organize the delivery of the new model version into production.
💡 You might be also interested in our article ‘Key MLOps processes (part 2): Feature engineering, or the development of features’ → https://hystax.com/key-mlops-processes-part-2-feature-engineering-or-the-development-of-features.
✔️ OptScale, a FinOps & MLOps open source platform, which helps companies optimize cloud costs and bring more cloud usage transparency, is fully available under Apache 2.0 on GitHub → https://github.com/hystax/optscale.



