If you regularly read articles on MLOps, you begin to form a certain perception of the context. Thus, the authors of the texts mostly write about working with three types of artifacts:
- Data,
- Model,
- Code.
In general, this is enough to explain the essence of MLOps. The ML team must create a code base by which to implement an automated and repeatable process:
- Training on quality datasets for new versions of ML models,
- Delivering updated versions of the models to the final client services to handle incoming requests.
Let us now detail these aspects.
Data
If you regularly read articles on MLOps, you begin to form a certain perception of the context. Thus, the authors of the texts mostly write about working with three types of artifacts:
- Data,
- Model,
- Code.
In general, this is enough to explain the essence of MLOps. The ML team must create a code base by which to implement an automated and repeatable process:
- Training on quality datasets for new versions of ML models,
- Delivering updated versions of the models to the final client services to handle incoming requests.
Let us now detail these aspects.
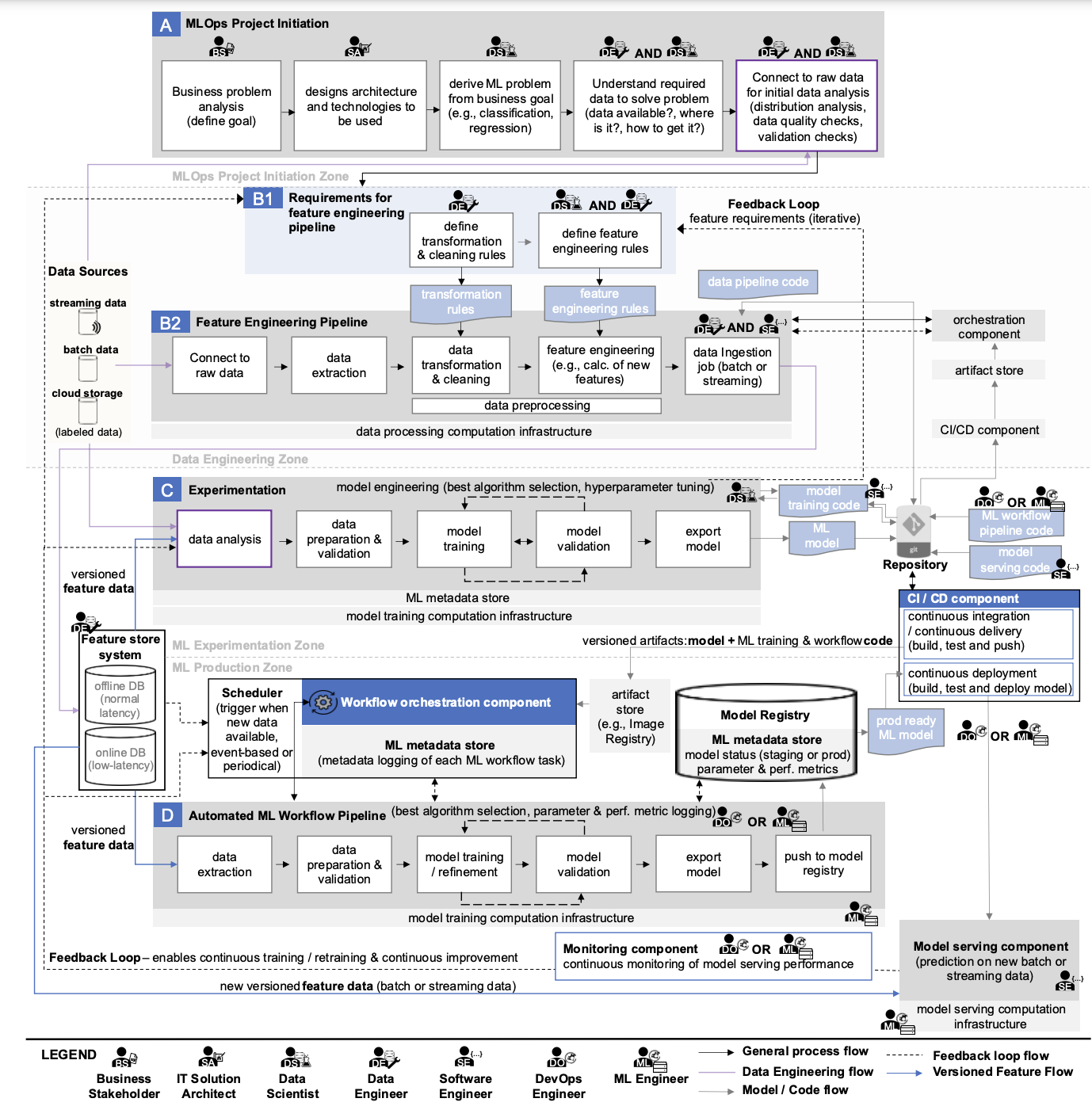
If you carefully look at the diagram that we examined in detail in the previous text, you can find the following “data sources”:
- Streaming data,
- Batch data,
- Cloud data,
- Labeled data,
- Feature online DB,
- Feature offline DB.
It is controversial to call this list sources, but the conceptual idea should be clear. There is data stored in a large number of systems and processed differently. All of them may be required for an ML model.
What to do to get the necessary data into the ML system:
- Use tools and processes that allow you to retrieve data from sources, create datasets from them, and expand them with new features, which are then saved in the corresponding databases for general use,
- Implement monitoring and control tools because data quality may change,
- Add a catalog that simplifies data search if there is a lot of it.
As a result, the company may have a full-fledged Data Platform with ETL/ELT, data buses, object stores, and other Greenplum.
The key aspect of using data in MLOps is the automation of preparing high-quality datasets for ML model training.

Model
Now let’s look for artifacts on the diagram that relate to ML models:
- ML model,
- Prod-ready ML model,
- Model Registry,
- ML Metadata Store,
- Model Serving Component,
- Model Monitoring Component.
We also need tools that will help to:
- Find the best parameters of ML models by conducting multiple experiments,
- Save the best models and sufficient information about them in a special registry (so that the results of experiments can be reproduced in the future),
- Organize the delivery of the best models to end-client services,
- Perform quality monitoring of their work so that, if necessary, new models can be trained automatically.
The key aspect of working with models in MLOps is the automation of the process of retraining models to achieve better quality metrics of their work with client requests.
Code
Code makes things easier: it automates processes for working with data and models.
On the diagram above, you can find references to:
- Data transformation rules,
- Feature engineering rules,
- Data pipeline code,
- Model training code,
- Machine learning (ML) workflow code,
- Model serving code.
Additionally, infrastructure as a code (IaaC) can be added to set up all necessary infrastructure.
It’s worth noting that there may sometimes be additional code for orchestration, especially if multiple orchestrators are used in the team. For example, Airflow can be used to launch DAGs in Dagster.
Infrastructure for MLOps
In the diagram, we see several types of computational infrastructure used:
- Data processing computational infrastructure,
- Model training computational infrastructure,
- Model serving computational infrastructure.
The last one is used both for conducting experiments and for retraining models within automated pipelines. This approach is possible if the utilization of computational infrastructure has enough capacity to perform these processes simultaneously.
In the initial stages, all tasks can be solved within one infrastructure, but in the future, the need for new resources will grow, particularly due to specific requirements for the configurations of computational resources:
- For training and retraining models, it is not necessary to use the most powerful Tesla A100 GPU; a simpler option like Tesla A30 or cards from the RTX A-Series (A2000, A4000, A5000) can be selected.
- For serving, Nvidia has the Tesla A2 GPU, which is suitable if your model and data batch for processing do not exceed the size of its video memory; if they do, select from GPUs in the first point.
- For data processing, a video card may not be required at all since this process can be built on a CPU. However, the choice here is even more difficult; AMD Epyc, Intel Xeon Gold, or modern desktop processors can be considered.
The widespread adoption of Kubernetes as an infrastructure platform for ML systems adds complexity. All computational resources must be able to be used in k8s.
Therefore, the big picture of MLOps is just the top level of abstraction that needs to be dealt with.
Reasonable and Medium Scale MLOps
After considering such an extensive diagram and mentioned artifacts, the desire to build something similar in your own company might disappear. It is necessary to choose and implement many tools, prepare the necessary infrastructure for them, teach the team to work with all of this, and also maintain all of the above.
The main thing in this business is to start. It is not necessary to implement all components of MLOps at once if there is no business need for them. Using maturity models, a foundation can be created around which an ML platform will develop in the future.
It is quite possible that many components will never be needed to achieve business goals. This idea is already actively promoted in various articles about reasonable and medium-scale MLOps.
💡Like most IT processes, MLOps has maturity levels. They help companies understand where they are in the development process and what needs to be changed.
You might be also interested in our article ‘MLOps maturity levels: the most well-known models’ → https://hystax.com/mlops-maturity-levels-the-most-well-known-models.
✔️ OptScale, a FinOps & MLOps open source platform, helps companies run ML/AI or any type of workload with optimal performance and infrastructure cost. The platform is fully available under Apache 2.0 on GitHub. Optimize cloud spend and get a full picture of utilized cloud resources and their usage details → https://github.com/hystax/optscale.





