Efficient data management: reducing backup size with deduplication and compression
Data continues to expand due to its increasing utilization across society, the business sector, and globally. As the volume of data being processed rises, so does the need for greater storage capacity. However, backing up large amounts of data presents challenges such as high costs and inefficient use of bandwidth and storage resources. What if we could reduce the storage burden by preserving data and information more efficiently and cost-effectively?
Data reduction techniques provide a viable solution to storage challenges by allowing data to be minimized without sacrificing crucial information or integrity. These methods enable individuals, businesses, and organizations to back up data in a more compact format, reducing bandwidth usage and ensuring that the stored information remains accessible and intact.
This article delves into the primary techniques for reducing backup size: deduplication and compression. It also assesses the benefits and drawbacks of these methods and determines the most effective approach for minimizing backup size.
Why are data reduction techniques essential?
Data reduction techniques are vital for addressing the issues associated with large data files. They offer solutions for efficiently storing data to cut costs, save space, and reduce bandwidth usage, all while preserving data integrity and preventing loss.
Businesses, organizations, and individuals can store data in a more compact format, optimizing storage capacity and bandwidth using deduplication and compression methods. These techniques ensure no negative trade-offs when reducing backup file sizes, as all data—whether redundant or unique—can be accessed when needed. Additionally, smaller data sizes simplify data management and access, improving productivity.
Let’s explore these data reduction methods in detail, including how they work and whether they are necessary and worthwhile for reducing backup sizes.
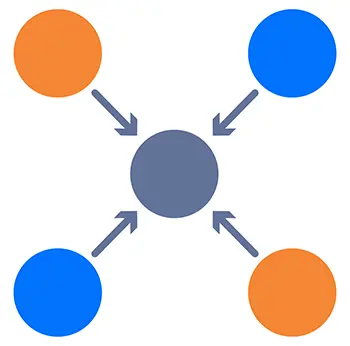
What is deduplication?
Data deduplication is a technique that reduces storage requirements by eliminating duplicate data. It identifies and removes redundant data blocks, keeping only one instance of each block. References to the removed duplicates are maintained and will be restored if needed.
For instance, when backing up a folder, the deduplication algorithm scans for duplicate data blocks. It identifies and retains only one copy of each unique block, indexing the data for accurate reconstruction when necessary. This process ensures that only distinct data blocks are stored, making it possible to reconstruct the original data as required.
Deduplication methods
There are several approaches to deduplicating data blocks, but we will focus on the three primary techniques:
Inline deduplication
Inline deduplication processes data in real-time. As data is backed up, the algorithm scans for redundant information, removing duplicate data and only sending unique blocks to the backup destination.
Post-process deduplication
Unlike inline deduplication, post-process deduplication does not filter out redundant data in real-time. Instead, it deduplicates the data after it has been backed up. While this method achieves the same result as inline deduplication, it requires more storage space and bandwidth since all data must be saved before duplicates are removed.
Global deduplication
Global deduplication integrates both inline and post-process methods. It involves a comprehensive deduplication process that checks for duplicates across the entire dataset, ensuring every redundant block is noticed.
Advantages of deduplication
Data retention: Deduplication ensures no data is lost during the reduction process. Although redundant data is removed, the original data can be fully recovered.
Reduced bandwidth consumption: By eliminating duplicate data, deduplication lowers the bandwidth required for backup and data transfer.
Cost efficiency: Smaller data sizes reduce storage costs, making deduplication cost-effective.
Improved performance: With reduced data sizes, the backup process becomes faster and more efficient, saving time and money.
Disadvantages of deduplication
Potential data integrity issues: If there is a mix-up, there is a risk of data corruption, and if the reference block is lost, all dependent blocks may also be lost.
Complexity: Implementing deduplication often requires additional hardware resources, making the process more complex and costly.
Limited effectiveness: Deduplication is less effective when data lacks redundancy, as it relies on the presence of duplicate data to reduce storage requirements.

What is compression?
Compression reduces the size of data files by encoding or altering them to make them smaller and more compact; unlike deduplication, which operates at the block level, compression functions at the file level. During compression, the algorithm identifies and removes duplicated or non-essential information without affecting the quality of the original content. The redundant data is discarded, and the remaining information is reorganized.
Compression methods
Lossy compression
Lossy compression reduces file sizes by discarding less critical parts of multimedia files. For instance, an audio file can be compressed into MP3 format, significantly reducing its size while removing inaudible frequencies and other non-essential elements. Although this results in some loss of audio quality, the final output remains acceptable. Similarly, RAW photographs can be compressed into JPEG format, where minor data loss occurs but does not noticeably impact the final image quality.
Lossless compression
Lossless compression reduces file sizes by identifying and eliminating redundancies while preserving the ability to reconstruct the original file. This method uses placeholders for repetitive data, allowing the original file to be accurately restored. Lossless compression is commonly used for data backup, where maintaining data integrity is crucial. It is also used to create ZIP files, which can be decompressed to retrieve the original files.
Advantages of compression
Reduced disk space: Compression decreases the storage needed, freeing up space for other uses.
Faster file transfer: Smaller file sizes lead to quicker transfer speeds, making backups and transfers more efficient.
Quicker read and write operations: Compressed files are faster to read and write than their original counterparts, improving operational efficiency.
Preserved data integrity: Compression maintains data integrity by ensuring no crucial information is lost when files are compressed into formats like ZIP.
Cost-effective storage: By making files more compact, compression reduces storage costs.
Disadvantages of compression
Decompression time: Decompressing large files can be time-consuming, potentially slowing overall operations. This represents a trade-off between reduced file size and decompression time.
Special decompression tools required: Decompressed files often require specific software, which may not be readily accessible to all users.
Increased memory usage: The compression process can demand additional memory resources, potentially causing issues on systems with limited memory.
Which data reduction technique is best for reducing backup size?
Deduplication is the most widely utilized method for reducing backup sizes, particularly for cloud storage backups. It effectively reduces data volume, helping to manage storage space and lower associated costs.
Deduplication ensures no data is lost during the reduction process by storing unique data blocks and referencing redundant ones. This guarantees that the original data remains intact and accessible whenever needed.
Compression is another technique used to reduce backup sizes. However, lossy compression is not suitable for backup purposes because it permanently discards some data elements, which can lead to the loss of critical information. Lossy compression best suits multimedia files like audio, video, and images. In contrast, lossless compression is appropriate for backup data as it retains the original data even after compression. While both deduplication and lossless compression can be used to minimize backup sizes, deduplication typically offers faster performance since it does not require decompression for data retrieval.
For optimal results, both techniques are recommended. First, deduplication to remove redundancy is applied, and then lossless compression to further reduce the file size. This approach will maximize storage efficiency and minimize backup costs.
Summing it up
In today’s data-rich environment, deduplication and compression are essential for managing backup sizes. The proliferation of information makes data backup costly and storage-intensive. Due to its efficiency and effectiveness, deduplication is the preferred method for reducing backup sizes. Lossless compression complements this by further condensing files without compromising data integrity.
Combining both techniques—deduplication followed by lossless compression—ensures the most efficient storage management. Deduplication addresses redundancy, while compression reduces file size, resulting in more compact and cost-effective backup solutions.
💡Utilizing Hystax Acura Disaster Recovery and Cloud Backup software is crucial for today’s companies to ensure Business Continuity, IT Resilience, protection against data loss, and resilient, efficient data storage with a deduplication ratio of up to 70%. We are always at your disposal if you have any questions about how to use it.