Desde o início do desenvolvimento do OptScale como produto, a Hystax busca as melhores e mais convenientes formas de Adoção dos princípios FinOps para nossos clientes. Uma das tarefas mais importantes e complexas em FinOps é envolver engenheiros no processo.
Uma maneira adequada de fornecer transparência aos recursos de TI para cumprir com os princípios básicos do FinOps

O problema com relação às ferramentas clássicas de gerenciamento de custos da nuvem, que são destinadas ao uso pela equipe financeira e apenas alguns (geralmente um ou dois) membros são do departamento de engenharia, é que elas fornecem uma visão de alto nível das despesas e tendências de uso da nuvem, o que mal pode ajudar alguns engenheiros a controlar as despesas de seus recursos de nuvem no trabalho diário.
É por isso que uma das principais visualizações que o OptScale fornece é a visualização de Recursos:
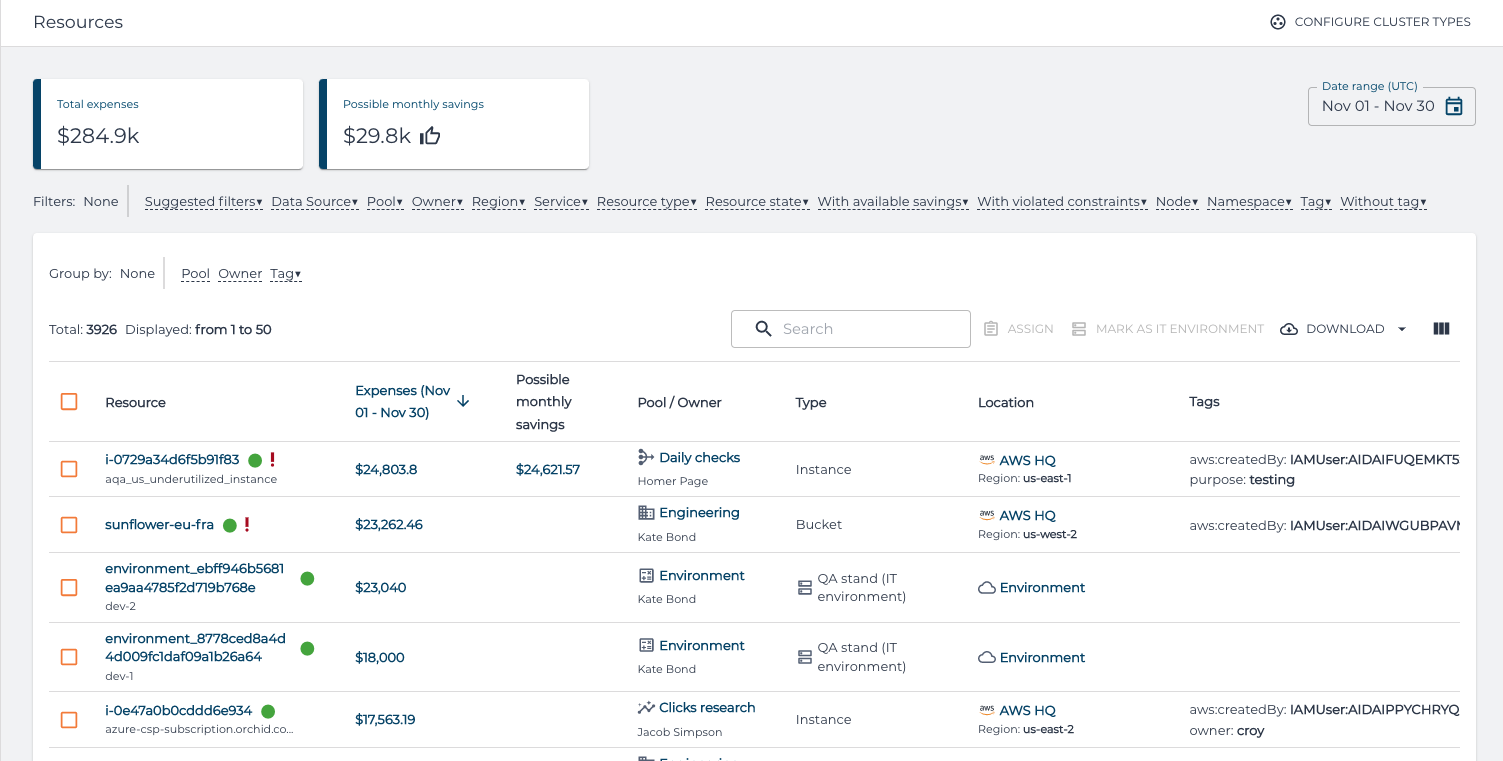
Com essa visão, é possível explorar recursos em todas as contas de nuvem conectadas, clusters Kubernetes ou ambientes registrados manualmente, especificando o intervalo de datas e aplicando os filtros necessários. Ao mesmo tempo, essa visão fornece informações atualizadas sobre despesas (e possíveis economias) para cada recurso específico. Essas informações combinadas permitem que os engenheiros supervisionem seus recursos e os envolvam no processo FinOps.
Otimização de custo de nuvem gratuita. Vida
Desafios computacionais com informações de recursos e despesas
Embora seja extremamente útil e flexível, a visualização Resources tem uma complexidade computacional significativa por trás. Por um lado, ela requer flexibilidade na filtragem de dezenas de milhares de recursos com propriedades dinâmicas. Por outro lado, ela precisa agregar despesas para todo o conjunto de recursos filtrados no intervalo de datas fornecido para mostrar os recursos de maior consumo e lidar com isso em tempo real.
Por muito tempo, a OptScale armazenou as informações de recursos e despesas em um banco de dados orientado a documentos. Essa decisão de arquitetura nos deu flexibilidade no armazenamento de metadados de recursos de nuvem e no uso de filtragem, pesquisa e processamento de recomendações. Essa flexibilidade nos permite implementar o suporte para qualquer propriedade de recurso de nuvem muito rápido e usá-lo quase imediatamente para fornecer recomendações de economia de custos e segurança.
O armazenamento orientado a documentos também é adequado para armazenar dados brutos de despesas. Cada provedor de nuvem tem um estrutura diferente de dados de faturamento eles fornecem. Além disso, há vários formatos de relatórios de faturamento, mesmo dentro de uma única nuvem. Então, um banco de dados orientado a documentos também é um lugar onde o OptScale armazena dados de despesas.
Mas, como desvantagem da flexibilidade de bancos de dados orientados a documentos, encontramos problemas com o desempenho da agregação de despesas. Você pode facilmente resumir as despesas de um único recurso, mas e se centenas de milhares de recursos, juntamente com suas despesas, precisassem ser agregados em uma solicitação do usuário? Isso nos forçou a implementar um conjunto de pipelines de pré-cálculo que eram executados após cada importação de dados de faturamento da nuvem, despesas agregadas para diferentes visualizações e resultados de cálculo armazenados para uso posterior. Essa abordagem nos permitiu fornecer tempos de resposta rápidos para solicitações pré-calculadas, mas introduziu complexidade adicional no produto e aumentou os esforços de manutenção de código.
Adoção do Clickhouse no OptScale
Paralelamente a isso, começamos a adotar um interessante e relativamente novo banco de dados de código aberto orientado a colunas chamado Casa de cliques, implementado inicialmente para processamento de dados em tempo real em uma plataforma de análise da web. Nós o usamos para armazenar e manipular em tempo real dados de desempenho de recursos de nuvem, e ficamos animados com o quão eficaz ele funcionou – durante nossos testes, obtivemos resultados de agregação incrivelmente rápidos para cada conjunto de dados de desempenho de recursos de nuvem da vida real que temos em produção. Ele também escala bem e tem uma estrutura de armazenamento eficaz, bem como requisitos significativos para o desempenho de armazenamento subjacente.
É por isso que, imediatamente após a implementação e os testes de campo do armazenamento Clickhouse para dados de desempenho de recursos de nuvem, começamos a projetar como podemos usá-lo para processamento de dados de faturamento.
A natureza dos bancos de dados colunares é que eles são realmente bons em novas inserções e agregações de dados, mas não são flexíveis o suficiente para alterar dados. E embora o histórico de medições de desempenho não esteja mudando, os dados de faturamento podem ser alterados ao longo do tempo devido às reconciliações de relatórios de faturamento na nuvem (na AWS, você pode até escolher como um relatório de faturamento alterado será entregue - como um novo arquivo ou uma versão anterior sobrescrita). Isso nos impediu de usar bancos de dados colunares para dados de faturamento antes e, claro, levantou o requisito correspondente para o banco de dados que poderíamos usar - o mecanismo de banco de dados não deve apenas lidar bem com os cenários "INSERT INTO" e "SELECT .. GROUP BY", mas também precisa ter uma maneira de operar com dados alterados. E, ao contrário da maioria dos outros bancos de dados orientados a colunas, o Clickhouse cobre esses cenários para armazenamento de dados de faturamento também - por meio do mecanismo de armazenamento especial chamado ColapsoMergeTree. Este mecanismo de armazenamento nos permite operar com dados em mudança em tempo real sem afetar a consistência da agregação e também fornece limpeza de fundo eficaz de dados obsoletos. Pode-se dizer que isso parece uma solução alternativa, mas este cenário parece um dos casos de uso que os desenvolvedores do Clickhouse tinham em mente ao implementar o mecanismo de banco de dados.
Como a implementação do Clickhouse aprimorou os recursos do OptScale
No momento, a implementação do processamento de dados de faturamento no OptScale apoiada pela Clickhouse é aplicada a vários grandes clientes, cada um deles com até um milhão de recursos de nuvem cobrados todo mês – e fornece análises precisas e muito rápidas com granularidade em nível de recurso para essas contas de nuvem.
Como resultado, o que a Hystax finalmente obteve com a adoção do mecanismo Clickhouse no OptScale:
- Armazenamento rápido e escalável para dados de faturamento
- Agregação e análise em tempo real de grandes conjuntos de dados
- Base de código de produto mais simples e fácil de manter, sem necessidade de pipelines de pré-cálculo.
É assim que escolher a ferramenta certa pode melhorar significativamente seu produto.
Encontre melhores práticas + dicas úteis para reduzir sua fatura da AWS → Como identificar e excluir instantâneos órfãos e não utilizados.