Embarcar na construção e utilização de um modelo de machine learning (ML) é um esforço cheio de nuances que exige planejamento meticuloso e esforço dedicado. Esse processo intrincado se desdobra por meio de cinco estágios essenciais dentro do ciclo de vida do machine learning, cada um com considerações críticas. Uma compreensão abrangente desse ciclo de vida capacita os cientistas de dados a alocar recursos e obter insights imediatos sobre sua progressão habilmente. Dentro dos limites deste artigo, nos aprofundamos nos estágios quintessenciais – abrangendo planejamento, preparação de dados, construção de modelo, implantação e monitoramento – oferecendo uma exploração detalhada de sua importância no machine learning.
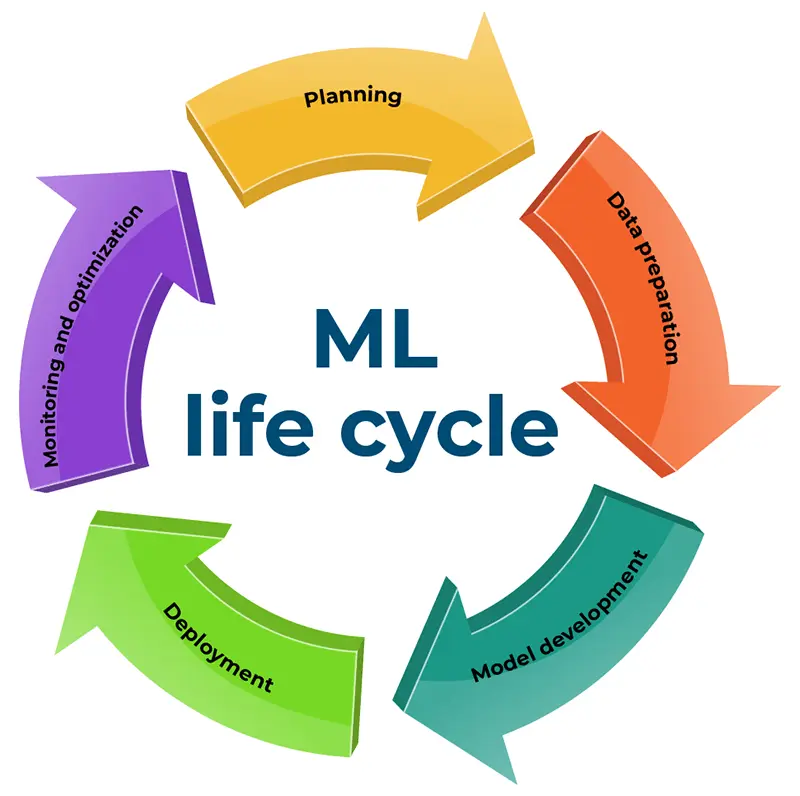
A importância de uma estrutura no ciclo de vida do ML
O ciclo de vida do Machine Learning orquestra a integração estratégica da inteligência artificial e do machine learning, traçando um curso desde a concepção do projeto até o desenvolvimento do modelo e as junções críticas de monitoramento e otimização. Além da narrativa habitual, essa jornada dinâmica se desenrola com o objetivo singular de abordar problemas específicos implantando um modelo de ML. No entanto, divergindo das perspectivas convencionais, ele ressalta a necessidade persistente de vigilância pós-implantação, enfatizando a otimização e a manutenção contínuas como salvaguardas indispensáveis contra a degradação do modelo e a invasão insidiosa do viés.

Otimização gratuita de custos de nuvem e gerenciamento aprimorado de recursos de ML/IA para toda a vida
Fases do desenvolvimento do Machine Learning
Embarcar na jornada de desenvolvimento do aprendizado de máquina requer uma exploração atenta de seu ciclo de vida diferenciado, composto por cinco estágios essenciais.
Planejamento pioneiro
Na gênese de cada expedição de desenvolvimento de modelo está uma fase crucial de planejamento. Este estágio envolve desvendar meticulosamente os problemas identificados com um olhar criterioso sobre a eficiência de recursos. O roteiro para o sucesso abrange o seguinte:
Na fase inicial do desenvolvimento do aprendizado de máquina, a precisão é primordial na definição do problema específico, seja abordando uma taxa de conversão lenta de clientes ou um aumento em atividades fraudulentas. Posteriormente, o processo exige a articulação de objetivos claros, delineando os resultados desejados, como amplificar as taxas de conversão de clientes ou reprimir comportamento fraudulento. Métricas cuidadosamente estabelecidas são aplicadas para avaliar o sucesso, com uma taxa de precisão de 70% considerada louvável, enquanto atingir uma taxa entre 70% e 90% é considerado o epítome do sucesso. Essa abordagem cuidadosa e sistemática ao planejamento define a base para um desenvolvimento bem-sucedido de modelo de aprendizado de máquina.
Preparação de dados
O segundo estágio no desenvolvimento de machine learning se concentra na aquisição e no refinamento meticulosos de dados. Dada a probabilidade de lidar com um volume substancial de dados, garantir sua precisão e relevância se torna imperativo antes de iniciar o processo de construção do modelo.
Este estágio fundamental de preparação de dados se desdobra por meio de várias etapas integrais. Inicialmente, a aquisição de um conjunto de dados substancial é considerada intensiva em recursos na Coleta e Rotulagem de Dados, estimulando a exploração da viabilidade de dados existentes. A integração de dados de diversas fontes e a alternativa de coleta de dados por meio de pesquisas, entrevistas ou observações são enfatizadas. A rotulagem de dados segue, atribuindo rótulos distintos a dados brutos, como imagens, vídeos ou texto, auxiliando na categorização e referência futura. Posteriormente, a Limpeza de Dados se torna primordial, com o tamanho do conjunto de dados correlacionando-se com a profundidade da limpeza necessária. A remoção prudente de valores ausentes e informações irrelevantes antes da construção do modelo é destacada para maior precisão e redução de erros e vieses. O ponto culminante envolve a Análise Exploratória de Dados (EDA), uma etapa fundamental que precede a construção do modelo, examinando o conjunto de dados por meio de visualizações para uma visão geral resumida, oferecendo insights valiosos sobre padrões prevalentes e promovendo uma compreensão diferenciada entre cientistas de dados.
Desenvolvimento de modelo
Com os dados preparados em mãos, o ponto focal muda para desenvolvimento de modelo, uma fase fundamental no ciclo de vida do aprendizado de máquina, abrangendo três subpontos principais:
- Seleção e avaliação do modelo: A etapa crítica é escolher o tipo de modelo. Cientistas de dados ajustam e testam vários modelos para identificar aquele que supera os demais. A seleção é tipicamente baseada na natureza dos dados, optando por um modelo de classificação ou regressão com a maior taxa de precisão.
- Treinamento de modelo: Passando para a fase de experimentação, os cientistas de dados inserem dados no algoritmo escolhido para extrair saídas iniciais. Esta fase revela os primeiros vislumbres da produção final, fornecendo insights que orientam modificações para previsões aprimoradas.
- Avaliação do modelo: Após concluir a fase de treinamento, o estágio final envolve uma revisão abrangente, examinando métricas como precisão e exatidão para avaliar o desempenho do modelo. Essa avaliação se estende a uma análise detalhada de erros e vieses, permitindo que os analistas criem soluções para sua eliminação. Se necessário, os cientistas de dados refinam e reexecutam o modelo iterativamente, incorporando aprimoramentos para elevar a precisão e o desempenho geral.
Implantação
A fase de implantação integra o modelo desenvolvido em um ambiente de produção existente, permitindo a tomada de decisões comerciais informadas. O estágio de implantação do modelo é um dos estágios mais desafiadores dentro do ciclo de vida do aprendizado de máquina; a implantação do modelo geralmente precisa ser abordada devido à disparidade entre as linguagens tradicionais de construção de modelos e os sistemas de TI de muitas organizações. Consequentemente, os cientistas de dados frequentemente se veem recodificando modelos para alinhá-los com os sistemas de produção, necessitando de um esforço colaborativo entre cientistas de dados e equipes de desenvolvimento (DevOps).
Monitoramento e otimização
Nos estágios culminantes, verificações de manutenção contínuas e otimizações periódicas são imperativas. Como os modelos podem se degradar ao longo do tempo, garantir sua precisão sustentada exige vigilância monitoramento e otimização. Esforços colaborativos entre cientistas de dados e a maioria dos engenheiros de software são geralmente essenciais, utilizando software de análise preditiva para identificar e retificar problemas como desvio ou viés do modelo. A análise preditiva, alavancando dados para discernir tendências do setor e melhores práticas, é vital na previsão da rotatividade de clientes ou na adaptação de campanhas de marketing para envolver interesse potencial.
Resumindo
Em conclusão, o ciclo de vida da aprendizagem de máquina é um estrutura fundamental, fornecendo aos cientistas de dados um caminho estruturado para se aprofundarem nas complexidades do desenvolvimento de modelos de machine learning. Guiado por essa estrutura abrangente, o gerenciamento do ciclo de vida do modelo de ML abrange uma jornada holística, começando com a definição meticulosa de problemas e culminando na otimização contínua do modelo. Como uma pedra angular para a proficiência em machine learning, essa estrutura de ciclo de vida encapsula a essência do desenvolvimento estratégico e informado de modelos, facilitando uma abordagem robusta para resolver problemas complexos e avançar o campo da inteligência artificial.
Escala Óptica, uma plataforma MLOps e FinOps de código aberto no GitHub, oferece transparência completa e otimização de despesas com nuvem em várias organizações e apresenta ferramentas MLOps, como ajuste de hiperparâmetros, experimentos de rastreamento, modelos de controle de versão e tabelas de classificação de ML →



