Por favor, considere dar ao OptScale umEstrela no GitHub, é código aberto 100%. Aumentaria sua visibilidade para outros e aceleraria o desenvolvimento de produtos. Obrigado!
Ebook 'De FinOps a estratégias comprovadas de gerenciamento e otimização de custos de nuvem'
Neste artigo, descrevemos o Processo 2 – Engenharia de recursos ou o desenvolvimento de recursos.
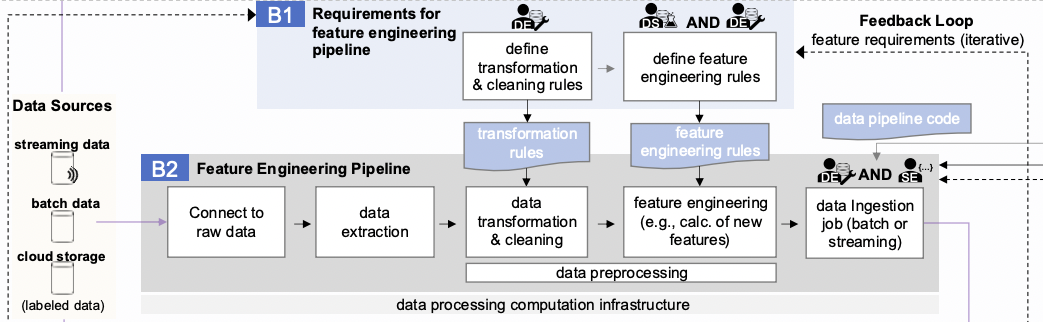
Por favor, encontre o esquema completo, que descreve os principais processos de MLOps aqui. As principais partes do esquema são blocos horizontais, dentro dos quais os aspectos procedimentais dos MLOps são descritos. Cada um deles é projetado para resolver tarefas específicas dentro da estrutura de garantir a operação ininterrupta dos serviços de ML da empresa.
Se as métricas desejadas de um modelo de ML não puderem ser alcançadas, pode-se tentar expandir a descrição de recursos de objetos de conjunto de dados com novos recursos. Ao fazer isso, o contexto para o modelo se expandirá e, portanto, as métricas desejadas podem melhorar.
Novos recursos podem incluir:
para dados tabulares: transformações arbitrárias de recursos de objetos existentes, como X^2, SQRT(X), Log(x), X1*X2, etc.,
com base na área temática: índice de massa corporal, número de pagamentos de créditos em atraso por ano, classificação do filme no IMDb, etc.
Vamos dar uma olhada na parte do esquema que se relaciona à engenharia de recursos.
Bloco B1 visa formar um conjunto de requisitos para transformar dados de origem existentes e obter características deles. O cálculo das características em si é baseado nesses dados pré-processados e limpos, de acordo com as fórmulas introduzidas pelo desenvolvedor de ML.
É importante notar que o processo de engenharia de recursos é iterativo. Aplicar um conjunto de recursos pode levar a novas ideias, que são implementadas em outro conjunto de recursos, e assim por diante indefinidamente. Isso é claramente mostrado no esquema como um Loop de Feedback.
O processo de adição de novos recursos aos dados é descrito no bloco B2 e inclui:
conectando-se a dados brutos,
extração de dados,
transformação e limpeza de dados,
engenharia de recursos,
e ingestão de dados.
Conectando-se a dados brutos
Conectar-se a dados brutos e extrair dados são operações técnicas que podem ser bastante desafiadoras. Para simplificar, vamos supor que há várias fontes às quais a equipe tem acesso e ferramentas para extrair dados dessas fontes (pelo menos scripts Python).
Transformação e limpeza de dados
Este estágio é quase idêntico ao passo similar no bloco de experimentos (C) – preparação de dados. De fato, no estágio dos primeiros experimentos, há uma compreensão de quais dados e em qual formato são necessários para o treinamento do modelo de ML. Resta apenas gerar e testar novos recursos corretamente, mas o processo de preparação de dados para isso deve ser automatizado o máximo possível.
Otimização gratuita de custos de nuvem e gerenciamento aprimorado de recursos de ML/IA para toda a vida
Conforme observado acima, essas ações podem consistir em simplesmente transformar vários elementos da tupla de dados. Outra opção é executar um pipeline de processamento grande separado para adicionar um recurso à mesma tupla. Em qualquer caso, há um conjunto de ações que são executadas sequencialmente.
Ingestão de dados
O resultado das ações anteriores é adicionado ao conjunto de dados. Os recursos são mais frequentemente adicionados ao conjunto de dados em lotes para reduzir a carga nos bancos de dados. Mas às vezes é necessário fazer isso na hora (streaming) para acelerar a execução de tarefas comerciais.
É importante usar os recursos obtidos da forma mais eficiente possível: salvá-los e reutilizá-los nas tarefas de outros desenvolvedores de ML na empresa. Para esse propósito, há um Feature store no esquema. Idealmente, ele deve estar disponível dentro da empresa, administrado separadamente e versionado para todos os recursos que entram nele. O Feature store em si tem duas partes: online (para cenários de streaming) e offline (para cenários em lote).
Poucos vão querer fazer tudo isso manualmente todas as vezes, principalmente porque todas as ações parecem facilmente automatizadas.
✔️ OptScale, uma plataforma de código aberto FinOps & MLOps, que ajuda empresas a otimizar custos de nuvem e trazer mais transparência ao uso da nuvem, está totalmente disponível no Apache 2.0 no GitHub → https://github.com/hystax/optscale.
Mantenha-se atualizado
Digite seu e-mail para ser notificado sobre conteúdo novo e relevante.
Obrigado por se juntar a nós!
Esperamos que você ache isso útil.
Você pode cancelar a assinatura dessas comunicações a qualquer momento. política de Privacidade
Uma descrição completa do OptScale como uma plataforma de código aberto FinOps e MLOps para otimizar o desempenho da carga de trabalho na nuvem e o custo da infraestrutura. Otimização de custo de nuvem, Dimensionamento correto de VM, instrumentação PaaS, Localizador de duplicatas S3,Uso RI/SP, detecção de anomalias, + ferramentas de desenvolvedor de IA para utilização ideal da nuvem.