From the very beginning of OptScale development as a product, Hystax is looking for the best and the most convenient ways of FinOps principles adoption for our customers. One of the most important and complex tasks in FinOps is to involve engineers into the process.
A proper way to provide IT resources transparency to comply with core FinOps principles

The issue regarding classic Cloud Cost Management tools, which are intended to be used by the Finance team and only several (usually one or two) members are from the Engineering department, is that they provide too high level view of the cloud usage expenses and trends which can barely help some engineers control expenses of their cloud resources in day-to-day work
That’s why one of the major views which OptScale provides is the Resources view:
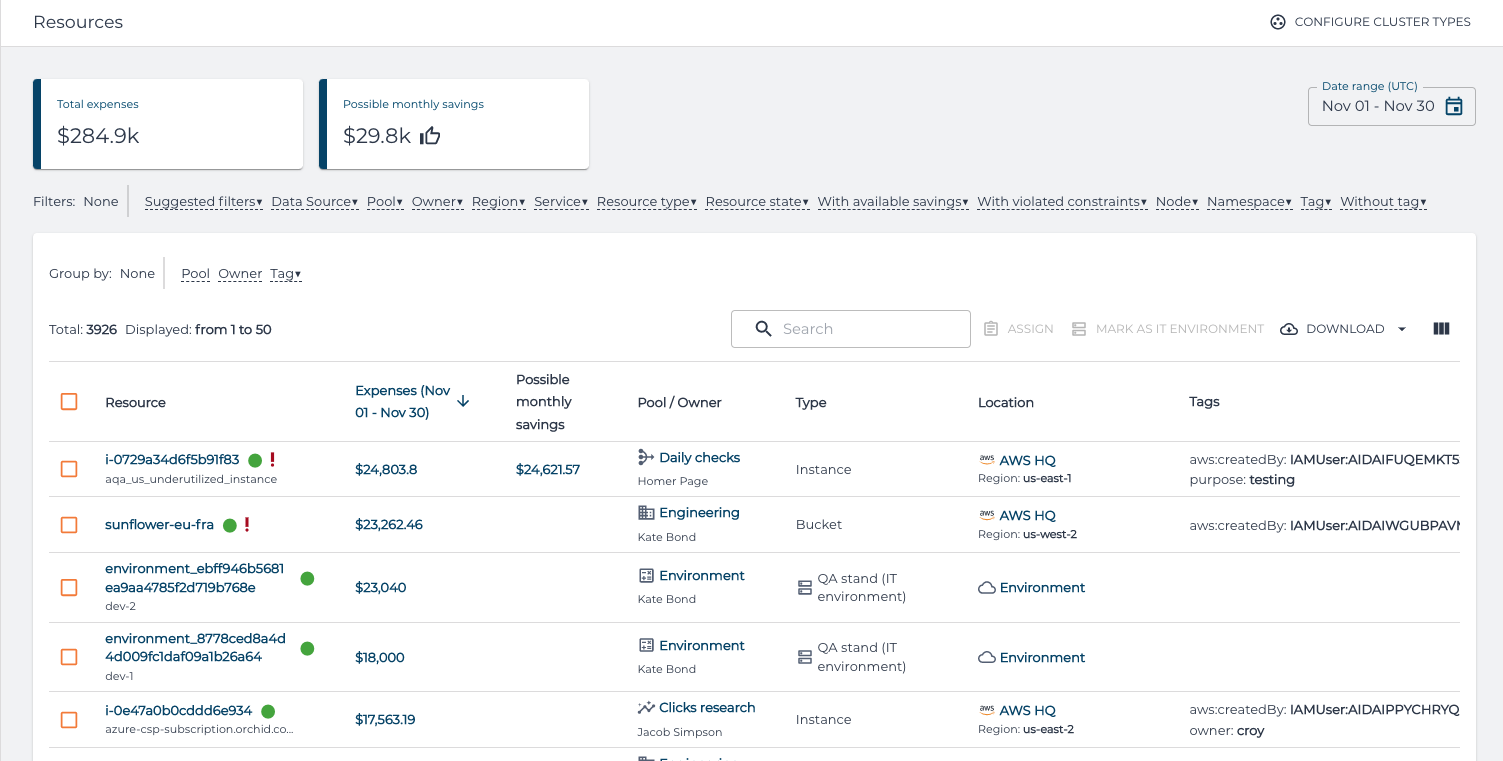
With this view, one can explore resources across all the connected cloud accounts, Kubernetes clusters or manually registered environments, specifying date range and applying necessary filters. At the same time, this view provides up-to-date information about expenses (and possible savings) for every specific resource. Such combined information allows engineers to oversee their resources and involve them in the FinOps process.
Free cloud cost optimization. Lifetime
Computational challenges with resource and expenses information
While being extremely useful and flexible, the Resources view has significant computational complexity behind. On one side, it requires flexibility in filtering tens of thousands of resources with dynamic properties. On the other side – it needs to aggregate expenses for the whole set of the filtered resources in the given date range to show top-consuming resources and handle this in a realtime.
For a long time, OptScale stored the resource and expense information in a document-oriented database. This architecture decision gave us flexibility in storing cloud resources metadata and using it filtering, search and recommendations processing. Such flexibility allows us to implement the support for any cloud resource property very fast and almost immediately use it for providing cost-saving and security recommendations.
Document-oriented storage also suits well for storing raw expenses data. Every cloud provider has a different structure of billing data they provide. Moreover, there are various billing report formats even inside a single cloud. So, a document-oriented database also is a place where OptScale stores expense data.
But, as the drawback of flexibility of document-oriented databases we have encountered issues with performance of expenses aggregation. You can easily summarize expenses of a single resource, but what if hundreds of thousands of resources along with their expenses should be aggregated on a user request? This forced us to implement a set of precalculation pipelines which were executed after every billing data import from the cloud, aggregated expenses for different views and stored calculation results for further use. Such an approach allowed us to provide rapid response times for precalculated requests, but introduced additional complexity into the product and increased code maintenance efforts.
Clickhouse adoption in OptScale
In parallel to that, we started to adopt an interesting and relatively new open-source column-oriented database called Clickhouse, initially implemented for real-time data processing in a web-analytics platform. We used it for storing and real-time handling of cloud resources performance data, and were excited how effective it worked – during our tests we got blazingly fast aggregation results for every real-life cloud resource performance dataset which we have in production. It also scales well and has an effective storage structure as well as meaningful requirements to underlying storage performance.
That’s why immediately after the implementation and field-testing of Clickhouse storage for cloud resource performance data, we started to design how we can use it for billing data processing.
The nature of columnar databases is that they are really good at new data inserts and aggregation, but not flexible enough for changing data. And while performance measurements historing is not changing, billing data can be changed over time due to cloud billing report reconciliations (in AWS, you can even choose how a changed billing report will be delivered – as a new file or an overwriting previous version). This held us from using columnar databases for billing data before, and of course, raised the corresponding requirement for the database we could use – the database engine should not only handle “INSERT INTO” and “SELECT .. GROUP BY” scenarios well, but also it needs to have a way to operate with changing data. And, unlike the majority of other column-oriented DBs, Clickhouse covers such scenarios for billing data storage as well – through the special storage engine called CollapsingMergeTree. This storage engine allows us to operate with real-time changing data without affecting aggregation consistency and also provides effective background cleanup of obsolete data. One can say that this looks like a workaround, but this scenario looks like one of the use cases which Clickhouse developers had in mind while implementing the database engine.
How Clickhouse implementation enhanced OptScale capabilities
At the moment, Clickhouse-backed implementation of the billing data processing in OptScale is applied to several big customers, each of those has up to one million cloud resources charged every month – and it provides accurate and very fast analytics with resource-level granularity for those cloud accounts.
As the result, what Hystax finally got with Clickhouse engine adoption in OptScale:
- Fast and scalable storage for billing data
- Real-time aggregation and analytics over huge datasets
- Simpler and more maintainable product codebase without need of precalculation pipelines.
That’s how choosing the right tool can significantly improve your product.
Find best practices + helpful tips to reduce your AWS bill → How to identify and delete orphaned and unused snapshots.