En este artículo, describimos el Proceso 2: Ingeniería de características o el desarrollo de características.
Por favor, encuentre el esquema completo, que describe los procesos clave de MLOps aquíLas partes principales del esquema son bloques horizontales, en cuyo interior se describen los aspectos procedimentales de MLOps. Cada uno de ellos está diseñado para resolver tareas específicas en el marco de garantizar el funcionamiento ininterrumpido de los servicios de ML de la empresa.
Si no se pueden lograr las métricas deseadas de un modelo de ML, se puede intentar ampliar la descripción de las características de los objetos del conjunto de datos con nuevas características. Al hacerlo, se ampliará el contexto del modelo y, por lo tanto, las métricas deseadas pueden mejorar.
Las nuevas características pueden incluir:
- para datos tabulares: transformaciones arbitrarias de características de objetos existentes, como X^2, SQRT(X), Log(x), X1*X2, etc.,
- basado en el área temática: índice de masa corporal, número de pagos de créditos vencidos por año, calificación de películas en IMDb, etc.
Veamos la parte del esquema que se relaciona con la ingeniería de características.
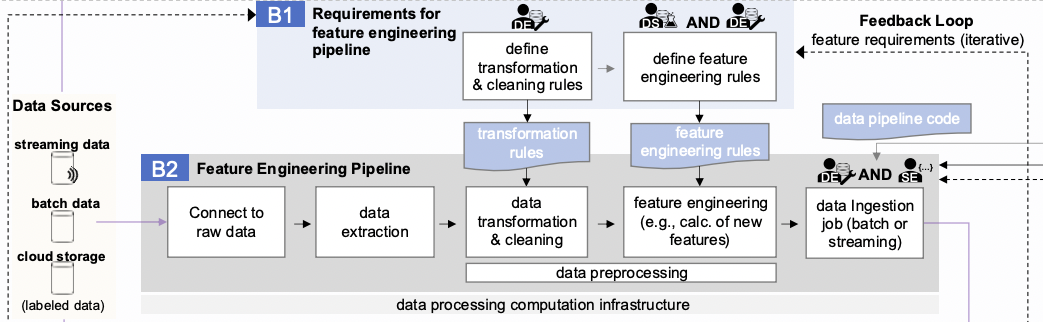
Bloque B1 El objetivo es crear un conjunto de requisitos para transformar los datos de origen existentes y obtener características a partir de ellos. El cálculo de las características en sí se basa en estos datos preprocesados y depurados, de acuerdo con las fórmulas introducidas por el desarrollador de ML.
Es importante tener en cuenta que el proceso de ingeniería de características es iterativo. La aplicación de un conjunto de características puede dar lugar a nuevas ideas, que se implementan en otro conjunto de características, y así sucesivamente indefinidamente. Esto se muestra claramente en el esquema como un bucle de retroalimentación.
El proceso de añadir nuevas características a los datos se describe en el bloque B2 e incluye:
- Conectarse a datos sin procesar,
- Extracción de datos,
- transformación y limpieza de datos,
- Ingeniería de características,
- y la ingesta de datos.
Conexión a datos sin procesar
La conexión a datos sin procesar y la extracción de datos son operaciones técnicas que pueden resultar bastante complicadas. Para simplificar, supongamos que existen varias fuentes a las que el equipo tiene acceso y herramientas para extraer datos de estas fuentes (al menos, scripts de Python).
Transformación y limpieza de datos
Esta etapa es casi idéntica a la etapa similar del bloque experimental (C): la preparación de los datos. De hecho, en la etapa de los primeros experimentos, se sabe qué datos y en qué formato se necesitan para el entrenamiento del modelo de ML. Solo queda generar y probar correctamente las nuevas características, pero el proceso de preparación de datos para esto debe automatizarse tanto como sea posible.

Optimización gratuita de costos de la nube y gestión mejorada de recursos ML/IA de por vida
Ingeniería de características
Como se indicó anteriormente, estas acciones pueden consistir simplemente en transformar varios elementos de la tupla de datos. Otra opción es ejecutar una gran secuencia de procesamiento independiente para agregar una característica a la misma tupla. En cualquier caso, existe un conjunto de acciones que se realizan de manera secuencial.
Ingestión de datos
El resultado de las acciones anteriores se agrega al conjunto de datos. Las características se agregan al conjunto de datos en lotes para reducir la carga en las bases de datos. Pero a veces es necesario hacerlo sobre la marcha (en streaming) para acelerar la ejecución de las tareas comerciales.
Es importante utilizar las características obtenidas de la forma más eficiente posible: guardarlas y reutilizarlas en las tareas de otros desarrolladores de ML en la empresa. Para ello, existe un almacén de características en el esquema. Lo ideal es que esté disponible dentro de la empresa, se administre por separado y tenga versiones para todas las características que ingresan en él. El almacén de características en sí tiene dos partes: en línea (para escenarios de transmisión) y fuera de línea (para escenarios por lotes).
Pocos querrán hacer todo esto manualmente cada vez, especialmente porque todas las acciones parecen fácilmente automatizables.
💡 También te puede interesar nuestro artículo 'Procesos clave de MLOps (parte 1): Experimentación, o el proceso de realizar experimentos' → https://hystax.com/key-mlops-processes-part-1-experimentation-or-the-process-of-conducting-experiments.
✔️ OptScale, una plataforma de código abierto FinOps y MLOps que ayuda a las empresas a optimizar los costos de la nube y brindar más transparencia en el uso de la nube, está completamente disponible en Apache 2.0 en GitHub → https://github.com/hystax/optscale.




