En este artículo, describimos el bloque D, dedicado al flujo de trabajo de aprendizaje automático automatizado.
Por favor, encuentre el esquema completo, que describe los procesos clave de MLOps aquíLas partes principales del esquema son bloques horizontales, dentro de los cuales se describen los aspectos procedimentales de MLOps (se les asignan las letras A, B, C, D). Cada uno de ellos está diseñado para resolver tareas específicas en el marco de garantizar el funcionamiento ininterrumpido de los servicios de ML de la empresa.

Desde el principio, nos gustaría mencionar que en este artículo, por sistema ML, nos referimos a un sistema de información que contiene uno o más componentes con un modelo entrenado que realiza alguna parte de la lógica general del negocio. Cuanto mejor desarrollado esté el modelo ML, mayor será el impacto de su funcionamiento. El modelo entrenado procesa un flujo entrante de solicitudes y proporciona algunas predicciones en respuesta, automatizando algunas partes del proceso de análisis o toma de decisiones.
El proceso de utilizar el modelo para generar predicciones se denomina inferencia y el proceso de entrenamiento del modelo se denomina entrenamiento. Gartner puede ofrecer una explicación clara de la diferencia entre ambos; en este caso, utilizaremos a los gatos como ejemplo.
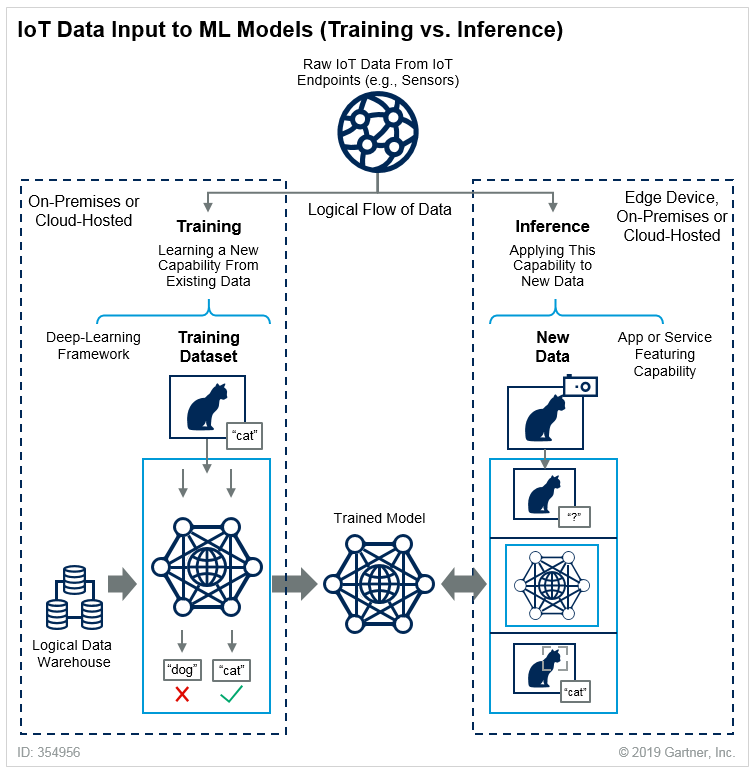
Para el Funcionamiento eficaz de un sistema ML de producciónEs importante monitorear las métricas de inferencia del modelo. Tan pronto como comienzan a disminuir, el modelo necesita ser reentrenado o reemplazado por uno nuevo. Esto suele suceder debido a cambios en los datos de entrada (desviación de datos). Por ejemplo, hay una tarea comercial en la que el modelo puede reconocer pan en fotos, pero en su lugar se le da una foto de un corgi. Los perros en el ejemplo son para el equilibrio:

El modelo del conjunto de datos inicial no sabía nada sobre los corgis, por lo que predice incorrectamente. Por lo tanto, es necesario cambiar el conjunto de datos y realizar nuevos experimentos. Al mismo tiempo, el nuevo modelo debe ponerse en producción lo antes posible. Los usuarios no tienen prohibido cargar imágenes de corgis, ya que obtendrán un resultado erróneo.
Ahora veamos más ejemplos de la vida real: Consideremos el sistema de recomendaciones de un mercado. En función del historial de compras de un usuario, las compras de usuarios similares y otros parámetros, un modelo o conjunto de modelos genera un bloque con recomendaciones. Incluye productos cuyos ingresos por compras se calculan y rastrean periódicamente.
Ocurre algo y las necesidades de los compradores cambian. Por lo tanto, las recomendaciones para ellos se vuelven obsoletas y la demanda de los productos recomendados disminuye. Todo esto conduce a una disminución de los ingresos.
A continuación, aparecen los gritos de los directivos y las exigencias de restaurar todo para mañana, que no conducen a nada. ¿Por qué? No hay suficientes datos sobre las nuevas preferencias de los compradores, por lo que ni siquiera se puede crear un nuevo modelo. Por supuesto, se pueden tomar algunos algoritmos básicos de generación de recomendaciones (filtrado colaborativo basado en artículos) y agregarlos a la producción. De esta manera, las recomendaciones funcionarán de alguna manera, pero es solo un "parche" temporal.
Lo ideal sería que el proceso se estableciera de tal manera que, en base a métricas y sin la guía de los gerentes, se lanzara el proceso de reentrenamiento o experimentación con diferentes modelos. Y el mejor eventualmente reemplazara al actual en producción. En el diagrama, esto es Canalización de flujo de trabajo de ML automatizado (bloque D), que se activa en alguna herramienta de orquestación.

Optimización gratuita de costos de la nube y gestión mejorada de recursos ML/IA de por vida
Esta es probablemente la sección más cargada del plan. El funcionamiento del Bloque D involucra varios componentes externos clave:
- El componente orquestador de flujo de trabajo es responsable de iniciar el flujo de trabajo en un cronograma o evento específico.
- El almacén de características proporciona datos sobre las características necesarias para el modelo.
- el registro de modelos y el almacén de metadatos de ML, donde se colocan los modelos y sus métricas obtenidas después de completar la canalización lanzada.
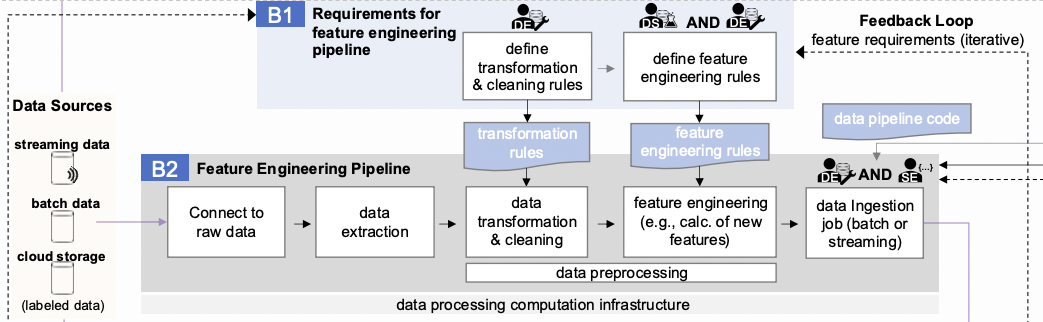
La estructura del bloque combina básicamente las etapas de experimentación (C) y desarrollo de características (B2). Esto no es sorprendente, dado que estos procesos necesitan ser automatizados. Las principales diferencias están en las dos últimas etapas:
- modelo de exportación
- Empujar al registro de modelos
Las demás etapas son idénticas a las descritas anteriormente.
Vale la pena destacar por separado la Artefactos de servicio requerido por el orquestador para lanzar los pipelines de reentrenamiento de modelos. De hecho, se trata de código que se almacena en un repositorio y se ejecuta en servidores dedicados. Está versionado y modernizado de acuerdo con todas las reglas del desarrollo de software. Es este código el que implementa el pipeline de reentrenamiento de modelos y el resultado depende de su corrección.
Cabe señalar que la automatización de experimentos en general es imposible. Por supuesto, se puede agregar el concepto de AutoML al proceso, pero hasta la fecha, no existe una solución reconocida que pueda usarse con los mismos resultados para cualquier tema de experimento.
En general, AutoML funciona de la siguiente manera:
- De alguna manera forma un conjunto de combinaciones de parámetros operativos del modelo.
- Lanza un experimento para cada combinación resultante.
- Registra las métricas de cada experimento, en función de las cuales se selecciona el mejor modelo.
En esencia, AutoML realiza todas las manipulaciones que un científico de datos hipotético de nivel junior o intermedio realizaría en un círculo de tareas más o menos estándar.
Hemos hablado un poco sobre la automatización. A continuación, es necesario organizar la entrega de la nueva versión del modelo a producción.
💡 También te podría interesar nuestro artículo 'Procesos clave de MLOps (parte 2): Ingeniería de características o desarrollo de características' → https://hystax.com/key-mlops-processes-part-2-feature-engineering-or-the-development-of-features.
✔️ OptScale, una plataforma de código abierto FinOps y MLOps que ayuda a las empresas a optimizar los costos de la nube y brindar más transparencia en el uso de la nube, está completamente disponible en Apache 2.0 en GitHub → https://github.com/hystax/optscale.




