En este artículo describimos el bloque del esquema, dedicado a servir y Monitoreo de modelos de aprendizaje automático.
Por favor, encuentre el esquema completo, que describe los procesos clave de MLOps aquíLas partes principales del esquema son bloques horizontales, en cuyo interior se describen los aspectos procedimentales de MLOps. Cada uno de ellos está diseñado para resolver tareas específicas en el marco de garantizar el funcionamiento ininterrumpido de los servicios de ML de la empresa.
Los modelos de aprendizaje automático en producción requieren la generación de predicciones. Sin embargo, el modelo de aprendizaje automático en sí es un archivo que no puede generar predicciones fácilmente. Una solución común que se encuentra en línea es que un equipo use FastAPI y escriba un contenedor de Python alrededor del modelo para "recuperar predicciones".

Si añadimos más detalles, hay varios escenarios posibles desde el momento en que el equipo recibe el archivo del modelo ML. El equipo puede:
- Escriba todo el código para configurar un servicio RESTful,
- Implemente todo el código envolvente necesario a su alrededor.
- Recopilar todo en una imagen de Docker,
- Finalmente, crea un contenedor a partir de esta imagen en algún lugar,
- Escalarlo de alguna manera,
- Organizar la recopilación de métricas,
- Configurar alertas,
- Establecer reglas para implementar nuevas versiones del modelo,
- y mucho más.
Hacer esto para todos los modelos y, al mismo tiempo, mantener la base de código en el futuro es una tarea laboriosa. Para facilitarlo, han surgido herramientas de servicio especiales que han introducido tres nuevas entidades en el sistema:
- Instancia/servicio de inferencia,
- Servidor de inferencia,
- Motor de servicio.
Un Instancia de inferencia o Servicio de inferencia es un modelo de ML específico preparado para recibir solicitudes y generar respuestas predictivas. En esencia, dicha entidad puede representarse mediante un contenedor con el equipamiento técnico necesario para su funcionamiento en un clúster de Kubernetes.
Un Servidor de inferencia Crea instancias/servicios de inferencia. Existen muchas implementaciones de servidores de inferencia, cada uno de los cuales puede funcionar con marcos de aprendizaje automático específicos, convirtiendo modelos entrenados en solicitudes de entrada listas para procesar y generando predicciones.
A Motor de servicio Realiza las principales funciones de administración. Determina qué servidor de inferencia se utilizará, cuántas copias de la instancia de inferencia recibida se deben iniciar y cómo escalarlas.
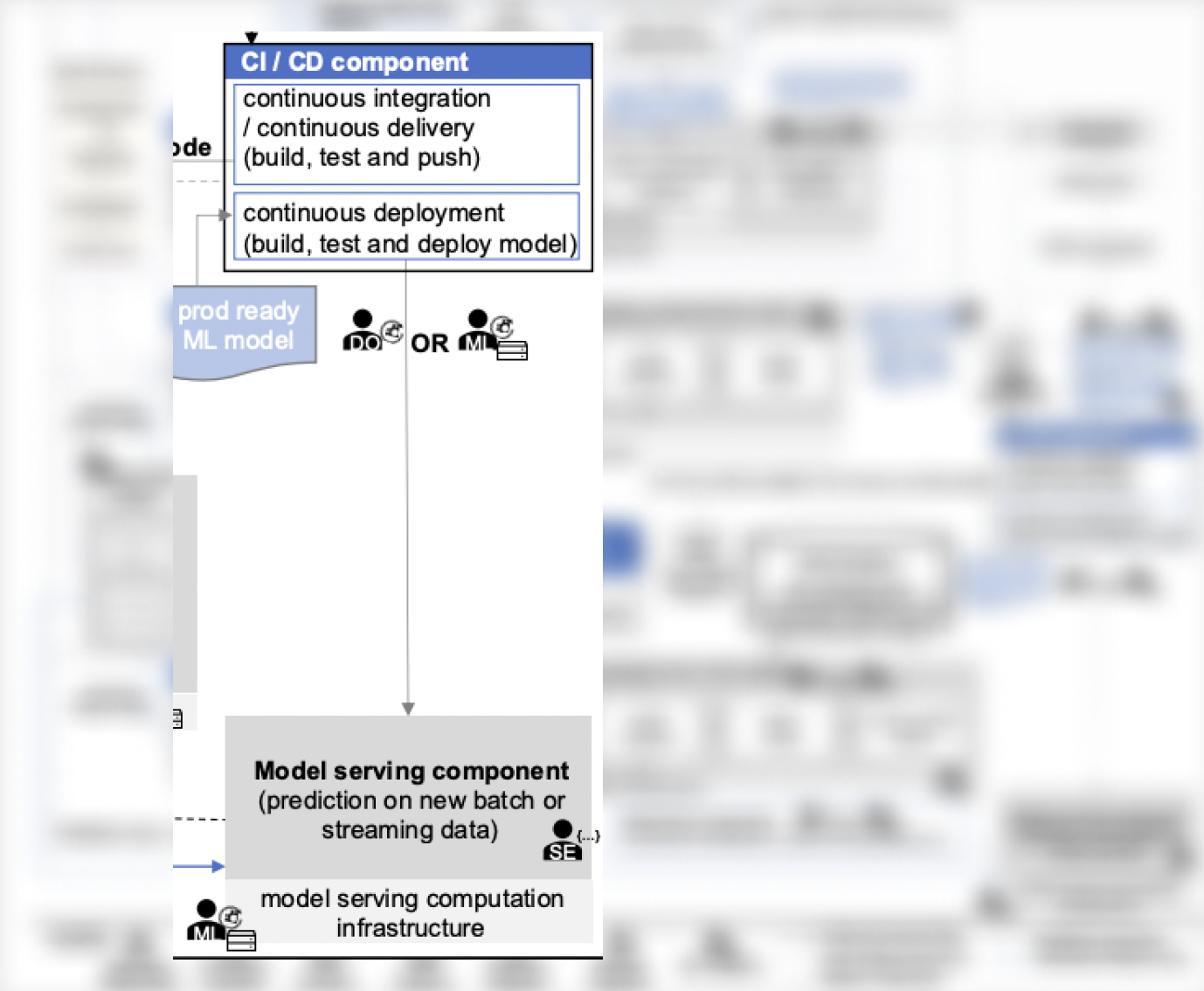
En el contexto del sistema analizado, no existe un modelo a nivel de componentes que proporcione detalles, pero hay aspectos similares:
- El CI/CD componente que maneja el despliegue de modelos listos para producción (puede considerarse una de las versiones de Serving Engine), y
Modelo de servicio, que organiza el esquema de generación de predicciones para modelos ML dentro de la infraestructura disponible, tanto para escenarios streaming como batch (puede considerarse una de las versiones de Inference Server).
Como ejemplo de una pila completa para servir, se puede hacer referencia a la Seldon pila:
- Núcleo Seldon es un motor de servicio,
- Servidor Seldon ML es un servidor de inferencia, que prepara el acceso al modelo a través de REST o gRPC,
- Tiempo de ejecución personalizado del servidor Seldon ML es una instancia de inferencia: un ejemplo de un contenedor para cualquier modelo de ML, cuya instancia debe iniciarse para generar predicciones.
Incluso existe un protocolo estandarizado para implementar Serving, cuyo soporte es de facto obligatorio en todas las herramientas similares. Se llama V2 Inference Protocol y fue desarrollado por varios actores importantes del mercado: KServe, Seldon, Nvidia Triton.

Optimización gratuita de costos de la nube y gestión mejorada de recursos ML/IA de por vida
Servir vs. implementar
En diversas fuentes, se puede encontrar la mención de las herramientas de “Servicio e Implementación” como un todo. Sin embargo, es importante entender la diferencia en su propósito. Este es un tema debatible, pero en este artículo lo abordaremos de la siguiente manera:
Servicio – se trata de crear una API de modelo y la capacidad de obtener predicciones a partir de ella, es decir, en última instancia, obtener una única instancia de servicio con un modelo en su interior.
Desplegar – se trata de distribuir la instancia de servicio en la cantidad necesaria para procesar las solicitudes entrantes (puede imaginar un conjunto de réplicas en la implementación de Kubernetes).
Existen muchas estrategias para implementar modelos, pero esto no es específico de ML. Por cierto, la versión paga de Seldon admite varias de estas estrategias, por lo que puedes elegir esta pila y disfrutar de cómo funciona todo por sí solo.
Es importante no olvidar que es necesario realizar un seguimiento de las métricas de rendimiento del modelo, de lo contrario no será posible resolver los problemas emergentes de manera oportuna. Cómo realizar el seguimiento de las métricas es una gran pregunta. La empresa Arize AI ha construido todo un negocio sobre esto, pero Grafana con VictoriaMetrics tampoco ha sido cancelada.
💡 También te puede interesar nuestro artículo 'Procesos clave de MLOps (parte 3): Flujo de trabajo de aprendizaje automático automatizado' → https://hystax.com/key-mlops-processes-part-3-automated-machine-learning-workflow.
✔️ OptScale, una plataforma de código abierto FinOps y MLOps que ayuda a las empresas a optimizar los costos de la nube y brindar más transparencia en el uso de la nube, está completamente disponible en Apache 2.0 en GitHub → https://github.com/hystax/optscale.



