Si lees regularmente artículos sobre MLOps, comienzas a formarte una cierta percepción del contexto. Así, los autores de los textos escriben principalmente sobre el trabajo con tres tipos de artefactos:
- Datos,
- Modelo,
- Código.
En general, esto es suficiente para explicar la esencia de MLOps. El equipo de ML debe crear una base de código mediante la cual implementar un proceso automatizado y repetible:
- Capacitación sobre conjuntos de datos de calidad para nuevas versiones de modelos ML,
- Entregar versiones actualizadas de los modelos a los servicios del cliente final para gestionar las solicitudes entrantes.
Ahora detallaremos estos aspectos.
Datos
Si lees regularmente artículos sobre MLOps, comienzas a formarte una cierta percepción del contexto. Así, los autores de los textos escriben principalmente sobre el trabajo con tres tipos de artefactos:
- Datos,
- Modelo,
- Código.
En general, esto es suficiente para explicar la esencia de MLOps. El equipo de ML debe crear una base de código mediante la cual implementar un proceso automatizado y repetible:
- Capacitación sobre conjuntos de datos de calidad para nuevas versiones de modelos ML,
- Entregar versiones actualizadas de los modelos a los servicios del cliente final para gestionar las solicitudes entrantes.
Ahora detallaremos estos aspectos.
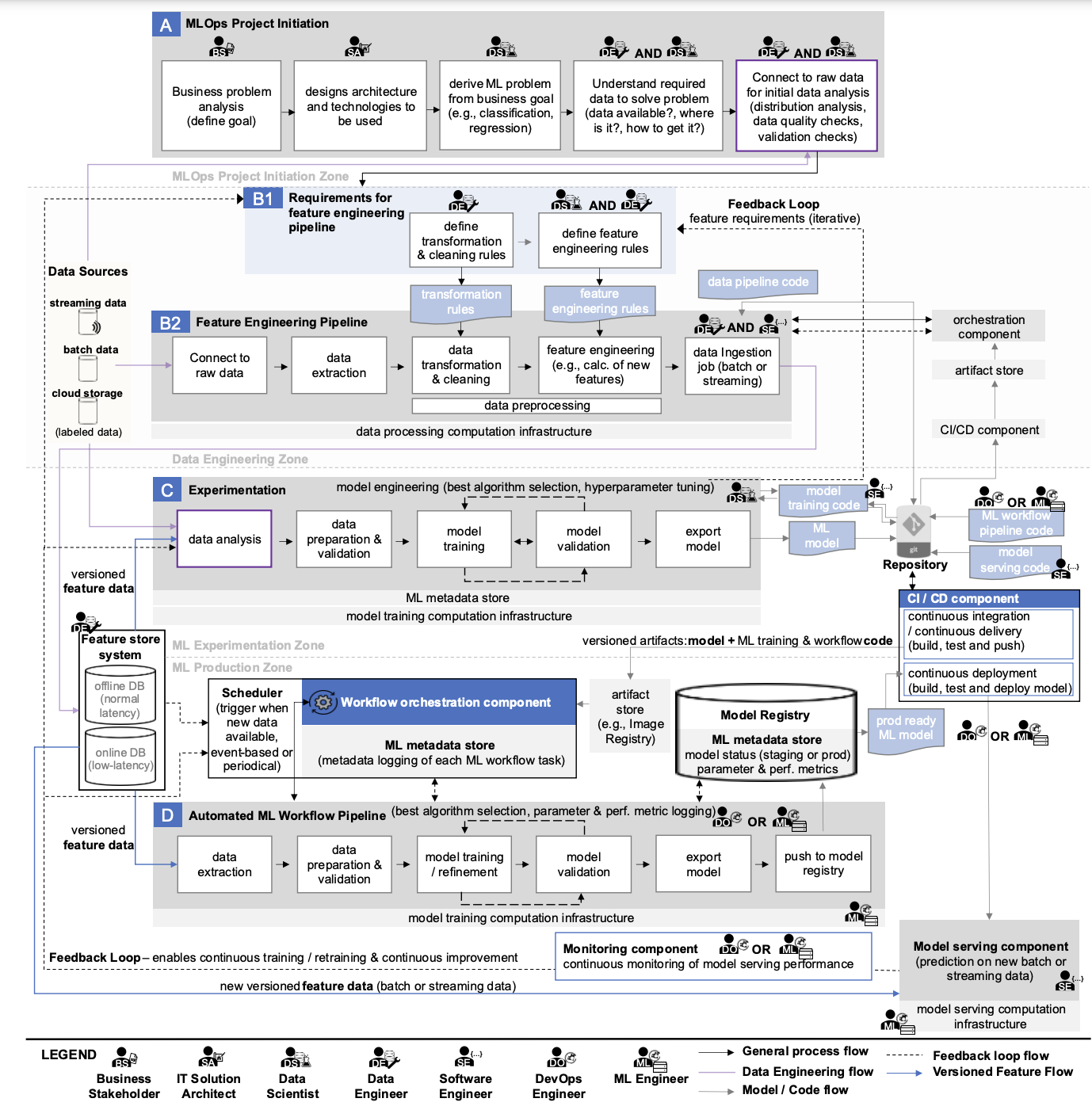
Si observas atentamente el diagrama que examinamos en detalle en el texto anterior, puedes encontrar las siguientes “fuentes de datos”:
- Transmisión de datos,
- Datos del lote,
- Datos en la nube,
- Datos etiquetados,
- Base de datos de características en línea,
- Característica de base de datos sin conexión.
Resulta controvertido llamar a esta lista fuentes, pero la idea conceptual debería ser clara. Hay datos almacenados en una gran cantidad de sistemas y procesados de forma diferente. Todos ellos pueden ser necesarios para un modelo de ML.
Qué hacer para obtener los datos necesarios en el sistema ML:
- Utilizar herramientas y procesos que permitan recuperar datos de fuentes, crear conjuntos de datos a partir de ellos y ampliarlos con nuevas características, que luego se guardan en las bases de datos correspondientes para uso general.
- Implementar herramientas de monitoreo y control porque la calidad de los datos puede cambiar,
- Agregue un catálogo que simplifique la búsqueda de datos si hay muchos.
Como resultado, la empresa puede tener una plataforma de datos completa con ETL/ELT, buses de datos, almacenes de objetos y otros Greenplum.
El aspecto clave del uso de datos en MLOps es la automatización de la preparación de conjuntos de datos de alta calidad para el entrenamiento del modelo ML.

Optimización gratuita de costos de la nube y gestión mejorada de recursos ML/IA de por vida
Modelo
Ahora busquemos artefactos en el diagrama que se relacionen con los modelos ML:
- Modelo ML,
- Modelo ML listo para producción
- Registro de modelos,
- Almacén de metadatos ML,
- Componente de servicio del modelo,
- Componente de Monitoreo de Modelos.
También necesitamos herramientas que ayuden a:
- Encuentre los mejores parámetros de los modelos ML realizando múltiples experimentos,
- Guardar los mejores modelos y suficiente información sobre ellos en un registro especial (para que los resultados de los experimentos puedan reproducirse en el futuro),
- Organizar la entrega de los mejores modelos a los servicios del cliente final,
- Realizar un seguimiento de la calidad de su trabajo para que, en caso necesario, se puedan entrenar nuevos modelos de forma automática.
El aspecto clave del trabajo con modelos en MLOps es la automatización del proceso de reentrenamiento de los modelos para lograr mejores métricas de calidad de su trabajo con las solicitudes de los clientes.
Código
El código facilita las cosas: automatiza los procesos para trabajar con datos y modelos.
En el diagrama anterior, puedes encontrar referencias a:
- Reglas de transformación de datos,
- Reglas de ingeniería de características,
- Código de canalización de datos,
- Código de entrenamiento del modelo,
- Código de flujo de trabajo de aprendizaje automático (ML),
- Código de servicio del modelo.
Además, se puede agregar infraestructura como código (IaaC) para configurar toda la infraestructura necesaria.
Vale la pena señalar que, en ocasiones, puede haber código adicional para la orquestación, especialmente si se utilizan varios orquestadores en el equipo. Por ejemplo, Airflow se puede utilizar para iniciar DAG en Dagster.
Infraestructura para MLOps
En el diagrama vemos varios tipos de infraestructura computacional utilizados:
- Infraestructura computacional de procesamiento de datos,
- Infraestructura computacional de entrenamiento de modelos,
- Modelo al servicio de la infraestructura computacional.
Este último se utiliza tanto para la realización de experimentos como para el reentrenamiento de modelos dentro de pipelines automatizados. Este enfoque es posible si la utilización de la infraestructura computacional tiene la capacidad suficiente para realizar estos procesos simultáneamente.
En las etapas iniciales, todas las tareas se pueden resolver dentro de una única infraestructura, pero en el futuro, la necesidad de nuevos recursos crecerá, en particular debido a los requisitos específicos para las configuraciones de los recursos computacionales:
- Para entrenar y reentrenar modelos no es necesario utilizar la GPU Tesla A100 más potente, sino que se puede optar por una opción más sencilla como la Tesla A30 o tarjetas de la serie RTX A (A2000, A4000, A5000).
- Para el servicio, Nvidia cuenta con la GPU Tesla A2, la cual es adecuada si tu modelo y lote de datos a procesar no exceden el tamaño de su memoria de video; si lo hacen, selecciona entre las GPU del primer punto.
- Para el procesamiento de datos, puede que no sea necesaria una tarjeta de vídeo, ya que este proceso puede realizarse en una CPU. Sin embargo, la elección aquí es aún más difícil: se pueden considerar procesadores AMD Epyc, Intel Xeon Gold o modernos para computadoras de escritorio.
La adopción generalizada de Kubernetes como plataforma de infraestructura para sistemas de aprendizaje automático agrega complejidad. Todos los recursos computacionales deben poder usarse en K8S.
Por lo tanto, el panorama general de MLOps es solo el nivel superior de abstracción que necesita abordarse.
MLOps de escala razonable y media
Después de considerar un diagrama tan extenso y los artefactos mencionados, es posible que desaparezca el deseo de construir algo similar en su propia empresa. Es necesario elegir e implementar muchas herramientas, preparar la infraestructura necesaria para ellas, enseñar al equipo a trabajar con todo esto y, además, mantener todo lo anterior.
Lo principal en este negocio es empezar. No es necesario implementar todos los componentes de MLOps a la vez si no existe una necesidad comercial para ellos. Mediante el uso de modelos de madurez, se puede crear una base sobre la cual se desarrollará una plataforma de ML en el futuro.
Es muy posible que muchos componentes nunca sean necesarios para alcanzar los objetivos de negocio. Esta idea ya se promueve activamente en varios artículos sobre MLOps razonables y de escala media.
Como la mayoría de los procesos de TI, MLOps tiene niveles de madurez. Estos ayudan a las empresas a comprender en qué etapa del proceso de desarrollo se encuentran y qué deben cambiar.
También te puede interesar nuestro artículo 'Niveles de madurez de MLOps: los modelos más conocidos' → https://hystax.com/mlops-maturity-levels-the-most-well-known-models.
✔️ OptScale, una plataforma de código abierto FinOps y MLOps, ayuda a las empresas a ejecutar ML/AI o cualquier tipo de carga de trabajo con un rendimiento y un coste de infraestructura óptimos. La plataforma está completamente disponible en Apache 2.0 en GitHub. Optimice el gasto en la nube y obtenga una imagen completa de los recursos de la nube utilizados y los detalles de su uso → https://github.com/hystax/optscale.



