A promising idea to use a Kubernetes container infrastructure for your business is gaining momentum. In the case of using K8s, you are most likely to face the question of managing expenses in clouds or an on-premise infrastructure to prevent budget overspending but possess a better performance simultaneously.

So, there is a list of today’s best practices that may be useful in optimizing your Kubernetes cloud costs.
- Pod rightsizing
- Node rightsizing (or virtual machine rightsizing)
- Autoscaling (horizontal pod autoscaling, vertical pod autoscaling, and cluster autoscaling)
- Rebalancing fragmented nodes
- Using cloud discount options (savings plans, reserved instances, spot, etc.)
Let’s examine all of them to highlight their meaningful features for managing cloud costs properly in a Kubernetes environment.
Cost optimization scenarios for Kubernetes
Pod rightsizing
Each Kubernetes cluster is considered as a set of pods that include containers. Being the smallest deployable elements, pods act as a single block of resources and allow you to run the workloads. You can manage CPU and RAM resources allocated for a specific pod. So, it’s essential to pay attention to the right size and schedule of the resources to maintain a cost-efficient and stable process in a pod’s environment. For this purpose, while configuring any Kubernetes cluster you need to adjust resource requests and limits to find an optimal amount of CPU and control memory resources per pod. That will provide you with a proper application performance and save compute and memory resources for other pods at the same node.
Otherwise, you may have a situation when you overcommit CPU and RAM but the overall VM or bare metal resources are underutilized and, if you remember, you don’t get them for free. This is a transition to the second point of node rightsizing.
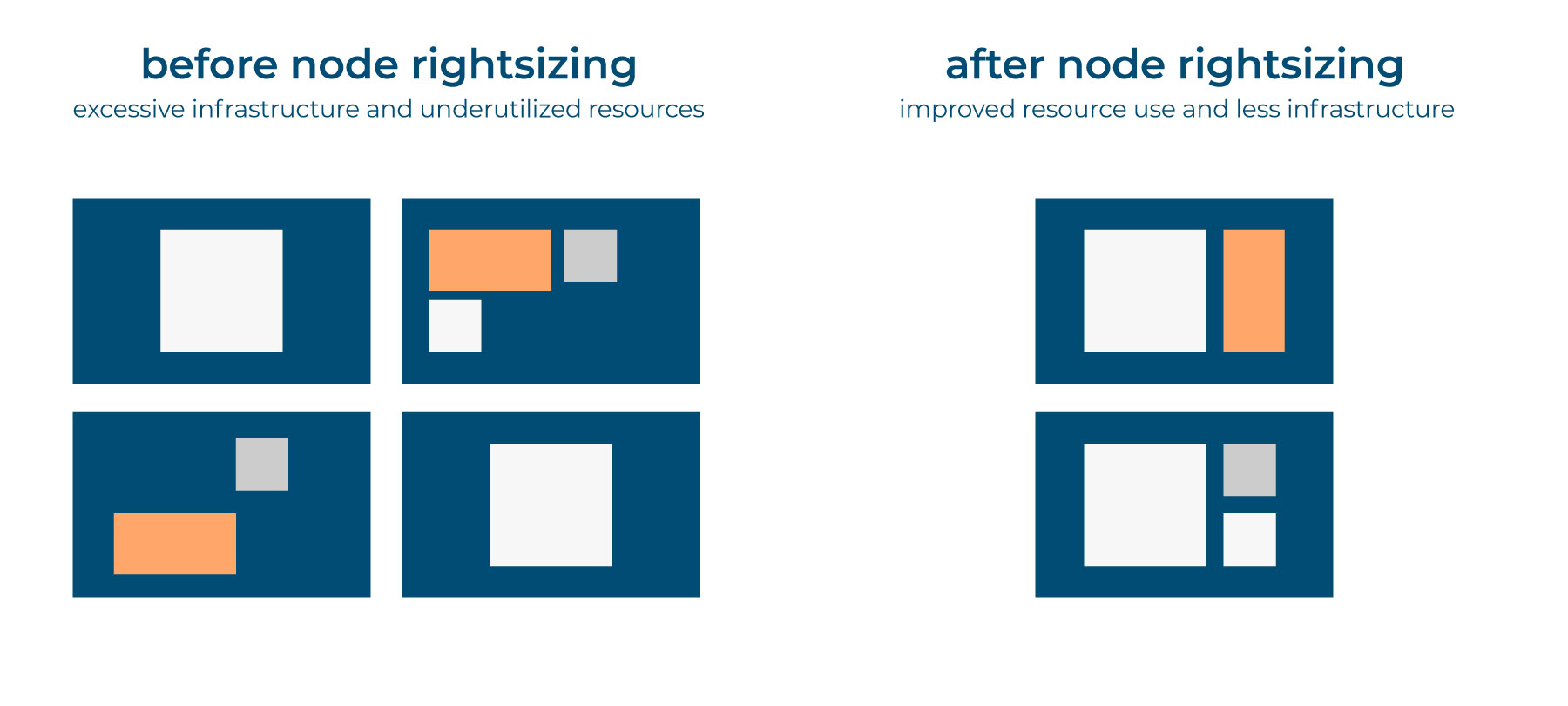
Node rightsizing (or virtual machine rightsizing)
Alongside with the rightsizing of the pods in a Kubernetes cluster environment, it makes sense to be sure the nodes you are using for your applications to run are also of the right size and flavor.
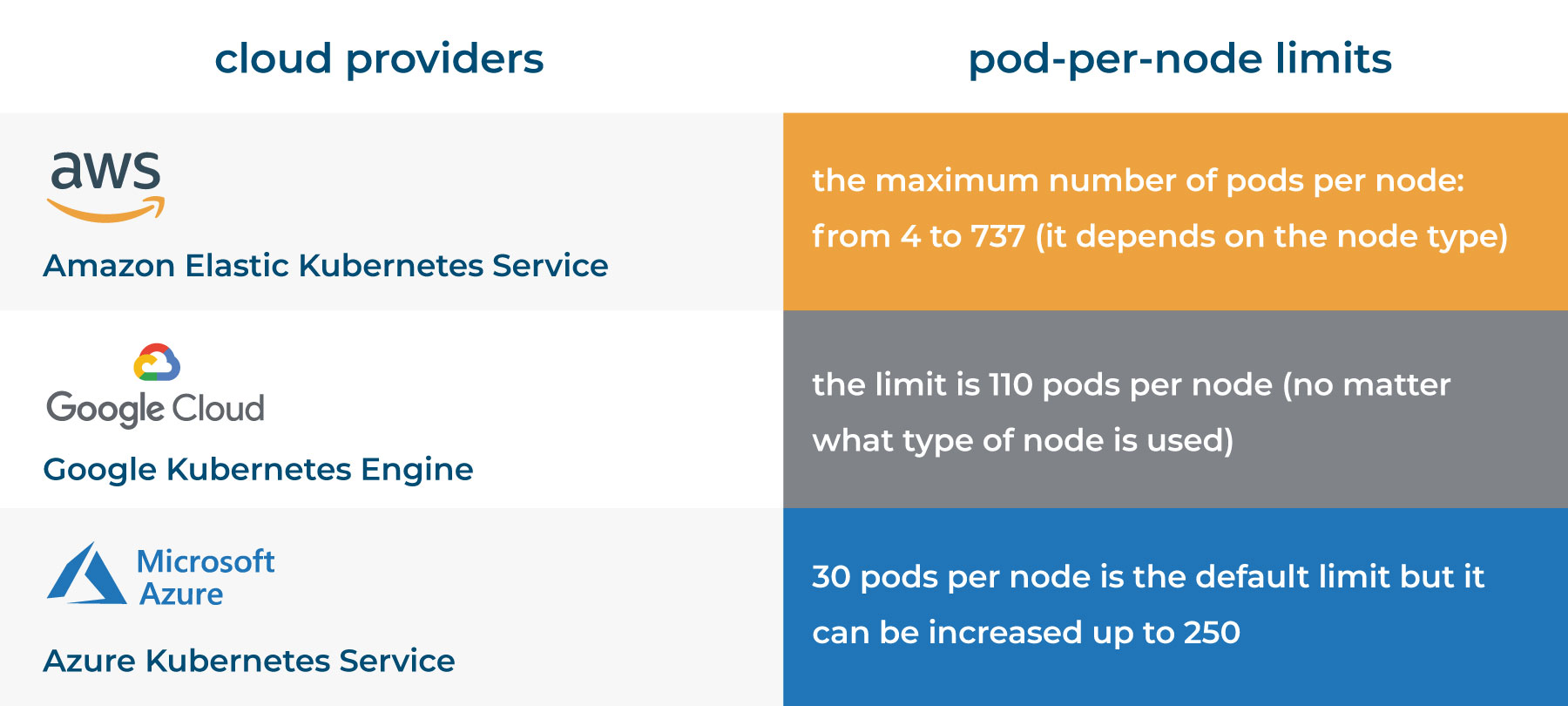
In terms of performance many things depend on a number of factors connected with how many pods per node become active while the workloads are running. Thus, it’s necessary to keep it in mind because on default even internal Kubernetes services themselves impose limits on the number of pods per node if it’s required.
At the table below you can find pod-per-node limits given by the leading cloud providers.
Hystax OptScale enables your team to achieve cloud cost efficiency in a cloud offering a number of features including rightsizing capabilities. A wide range of various optimization scenarios and real-time OptScale’s insights allow to track underutilized resources and downgrade them before they lead to an enormous budget exceed.
Autoscaling (horizontal pod autoscaling, vertical pod autoscaling, and cluster autoscaling)
Using those two aforementioned procedures (mentioned above) in a Kubernetes container environment is crucial to avoid poor application performance and overspending.
But also to reduce the cost of your Kubernetes cluster and provide a swift service adoption to any environment changes, Kubernetes has such autoscaling tools as The Horizontal Pod Autoscaler (HPA), The Vertical Pod AutoScaler (VPA) and The Cluster Autoscaler for managing the number of active pods and nods. They are best suited for setting the cost-optimized configuration, especially in cases of quick reaction to usage spikes and avoidance of workload instability. Cost saving happens when the tools are properly configured, and nodes are shut down or launched at the right time.
Rebalancing fragmented nodes
Over time any active Kubernetes cluster experiences a cycle of inevitable deployments and periodic scale-outs. That leads to repeated pod/nod additions and removals and it can cause an inefficient performance and resource fragmentation in a cluster.
Moreover, there is some kind of inconsistency in the Kubernetes scheduler work – they cannot fully predict a future number of nodes and what sizes pods will have. It means that even if some new pods are scheduled for the upcoming process and all the necessary resources requested by them are available, the resources collectively are unavailable at any single node that makes the pod unschedulable. So the extra scale-up is still needed even though the cluster as a whole unit has much more capacity available. The takeaway to get rid of a so-called “pseudo” resource crunch is consolidating all these available fragments of resources together.
That purpose of rebalancing fragmented nodes can be achieved by identifying and migrating a definite set of pods across the nodes in the cluster to combine all the necessary resources together. Especially, this procedure of rebalancing unoptimized Kubernetes clusters needs to be performed in large-scale clusters to avoid wastage of resources and reduce cloud costs.
Rebalancing fragmented nodes is an ongoing process and it usually cooperates with pods/nods rightsizing and autoscaling on the integrated basis.
Using cloud discounts options
Regarding a Kubernetes infrastructure it’s relevant to apply a set of resource purchasing options for the nodes where the cluster runs. Savings plans, on-demand instances, reserved instances, spot instances are available by the public cloud providers. You can find more information about those types of resources, discounts and tips on how to calculate them using the links below.
In general, you can save up to 50% of an IT cost using those programs so you need to consider them as one of the first steps that doesn’t interfere in your Kubernetes cluster or application architecture.
https://aws.amazon.com/savingsplans/
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/instance-purchasing-options.html
https://azure.microsoft.com/en-us/pricing/reserved-vm-instances/
https://hystax.com/what-are-the-main-challenges-of-cloud-financial-management-today/
https://hystax.com/cost-projection-to-reduce-cloud-costs/
https://hystax.com/spot-instances-for-ci-cd-jobs/
https://hystax.com/how-to-stop-paying-for-idle-cloud-instances-and-services/
Hystax OptScale offers hundreds of optimization scenarios.
Register now to get the recommendations → https://my.optscale.com/register