Neste artigo, descrevemos o bloco do esquema, dedicado ao atendimento e monitoramento de modelos de aprendizado de máquina.
Por favor, encontre o esquema completo, que descreve os principais processos de MLOps aqui. As principais partes do esquema são blocos horizontais, dentro dos quais os aspectos procedimentais dos MLOps são descritos. Cada um deles é projetado para resolver tarefas específicas dentro da estrutura de garantir a operação ininterrupta dos serviços de ML da empresa.
Os modelos de ML em produção exigem a geração de previsões. No entanto, o modelo de machine learning em si é um arquivo que não pode gerar previsões facilmente. Uma solução comum encontrada online é uma equipe usar FastAPI e escrever um wrapper Python em torno do modelo para “recuperar previsões”.

Se adicionarmos mais detalhes, há vários cenários possíveis a partir do momento em que a equipe recebe o arquivo do modelo ML. A equipe pode:
- Escreva todo o código para configurar um serviço RESTful,
- Implemente todo o código wrapper necessário em torno dele,
- Colete tudo em uma imagem Docker,
- Eventualmente, crie um contêiner desta imagem em algum lugar,
- Escale-o de alguma forma,
- Organizar coleta de métricas,
- Configurar alertas,
- Estabelecer regras para a implementação de novas versões do modelo,
- e muito mais.
Fazer isso para todos os modelos e, ao mesmo tempo, manter a base de código no futuro é uma tarefa trabalhosa. Para facilitar, ferramentas especiais de serviço surgiram e introduziram três novas entidades no sistema:
- Instância/Serviço de Inferência,
- Servidor de Inferência,
- Motor de serviço.
Um Instância de Inferência ou Serviço de Inferência é um modelo ML específico preparado para receber requisições e gerar respostas preditivas. Em essência, tal entidade pode ser representada por um contêiner com o equipamento técnico necessário para sua operação em um cluster Kubernetes.
Um Servidor de Inferência cria Instâncias/Serviços de Inferência. Há muitas implementações de Servidores de Inferência, cada um dos quais pode trabalhar com estruturas de ML específicas, convertendo modelos treinados em solicitações de entrada prontas para processar e gerando previsões.
UM Motor de serviço executa as principais funções de gerenciamento. Ele determina qual Inference Server será usado, quantas cópias da Inference Instance recebida precisam ser iniciadas e como escalá-las.
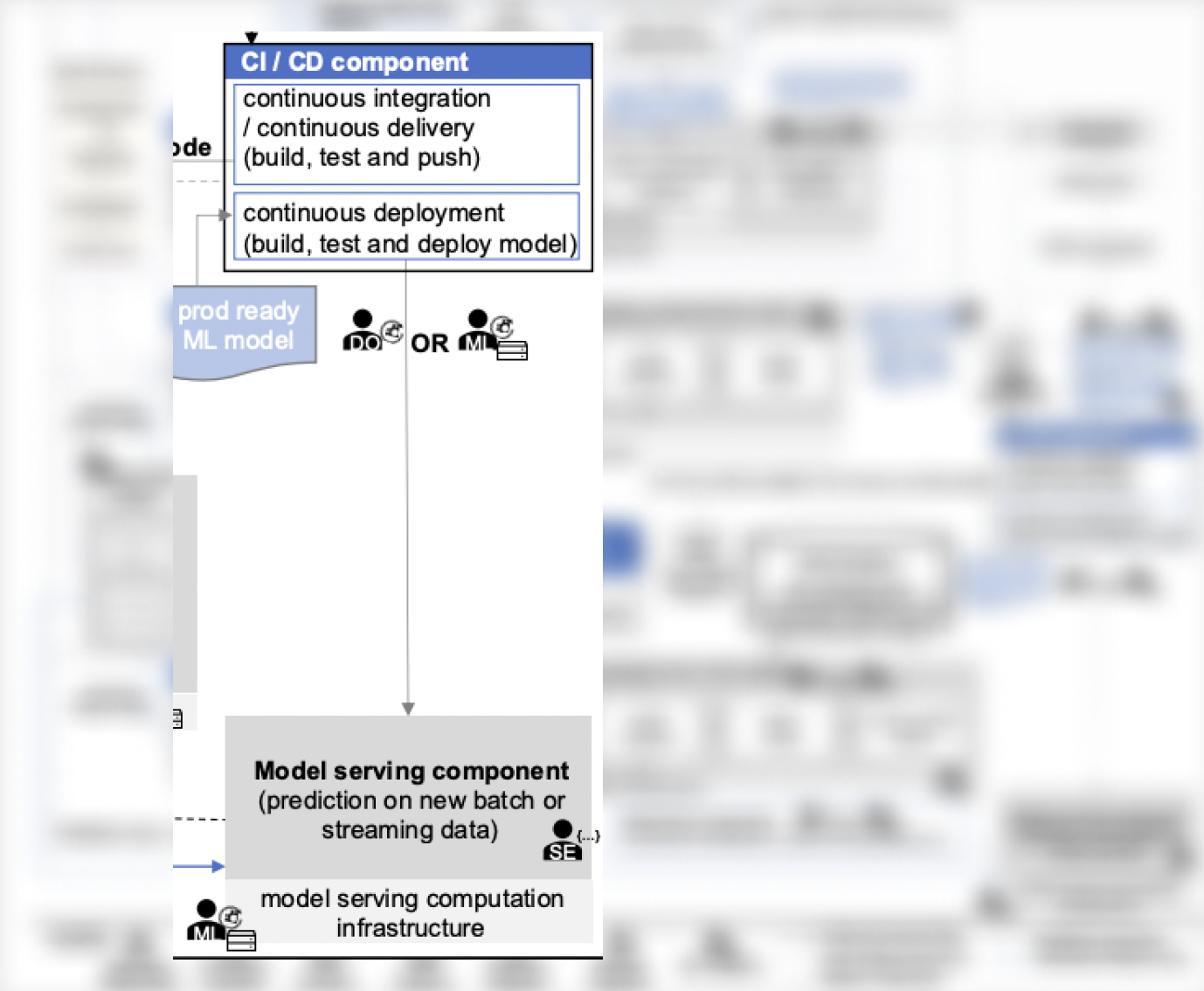
No contexto do sistema discutido, não há um modelo de nível de componente que sirva de detalhes, mas há aspectos semelhantes:
- O CI/CD componente que cuida da implantação de modelos prontos para produção (pode ser considerada uma das versões do Serving Engine), e
Modelo de serviço, que organiza o esquema para geração de previsões para modelos de ML dentro da infraestrutura disponível, tanto para cenários de streaming quanto em lote (pode ser considerada uma das versões do Inference Server).
Como exemplo de uma pilha concluída para Servir, pode-se consultar o Seldon pilha:
- Núcleo Seldon é um Motor de Serviço,
- Servidor Seldon ML é um servidor de inferência, que prepara o acesso ao modelo via REST ou gRPC,
- Tempo de execução personalizado do Seldon ML Server é uma Instância de Inferência – um exemplo de um wrapper para qualquer modelo de ML, uma instância do qual precisa ser iniciada para gerar previsões.
Existe até mesmo um protocolo padronizado para implementar o Serving, cujo suporte é de fato obrigatório em todas as ferramentas similares. Ele é chamado de V2 Inference Protocol e foi desenvolvido por vários grandes players do mercado – KServe, Seldon, Nvidia Triton.

Otimização gratuita de custos de nuvem e gerenciamento aprimorado de recursos de ML/IA para toda a vida
Servir vs. implantar
Em várias fontes, pode-se encontrar a menção das ferramentas “Serving e Deploy” como um todo. No entanto, é importante entender a diferença em seus propósitos. Esta é uma questão discutível, mas neste artigo, será como segue:
Servindo – trata-se de criar uma API de modelo e a capacidade de obter previsões a partir dela, ou seja, em última análise – obter uma única instância de serviço com um modelo dentro.
Implantar – trata-se de distribuir a instância de serviço na quantidade necessária para processar solicitações recebidas (você pode imaginar um conjunto de réplicas na implantação do Kubernetes).
Há muitas estratégias para implementar modelos, mas isso não é específico de ML. A versão paga do Seldon, a propósito, suporta várias dessas estratégias, então você pode simplesmente escolher essa pilha e aproveitar como tudo funciona por si só.
É importante não esquecer que as métricas de desempenho do modelo devem ser rastreadas, caso contrário, não será possível resolver problemas emergentes em tempo hábil. Como rastrear métricas é uma grande questão. A empresa Arize AI construiu um negócio inteiro com isso, mas o Grafana com VictoriaMetrics também não foi cancelado.
💡 Você também pode se interessar pelo nosso artigo 'Principais processos de MLOps (parte 3): Fluxo de trabalho automatizado de aprendizado de máquina' → https://hystax.com/key-mlops-processes-part-3-automated-machine-learning-workflow.
✔️ OptScale, uma plataforma de código aberto FinOps & MLOps, que ajuda empresas a otimizar custos de nuvem e trazer mais transparência ao uso da nuvem, está totalmente disponível no Apache 2.0 no GitHub → https://github.com/hystax/optscale.



