Diferentes empresas de vários perfis extraem valor dos dados. Até mesmo uma rede de pequenos salões de cabeleireiro em um bairro pode usar o Excel como seu sistema de CRM para acompanhar seus clientes. Com base em seus dados, você compilou uma lista de clientes que visitaram o salão pela última vez há algum tempo? É hora de enviar a eles um SMS com um desconto pessoal.
Em que ponto vale a pena para uma empresa criar uma plataforma de processamento de dados?
Do Excel ao ML: níveis de maturidade da análise de dados
No começo deste texto, mencionamos um pequeno salão de cabeleireiro. É um bom exemplo para continuar falando sobre o que está acontecendo em análise de dados. Para o resto da história, digamos que seja a rede de barbearias “The Barbershop”.

Abaixo está um modelo de maturidade para sistemas analíticos com base em Classificação de Gartner. Existem quatro níveis. Apenas algumas empresas progridem linearmente do início ao fim. Algumas empresas pulam rapidamente para os níveis 3 e 4. O mais importante é ter os recursos necessários – dinheiro, especialistas e objetivos de negócios. E algumas empresas permanecerão em planilhas do Excel e sistemas simples de BI. Isso também é normal.
Nossa “Barbearia” passará por cada estágio para facilitar a compreensão das diferenças nos níveis de maturidade.
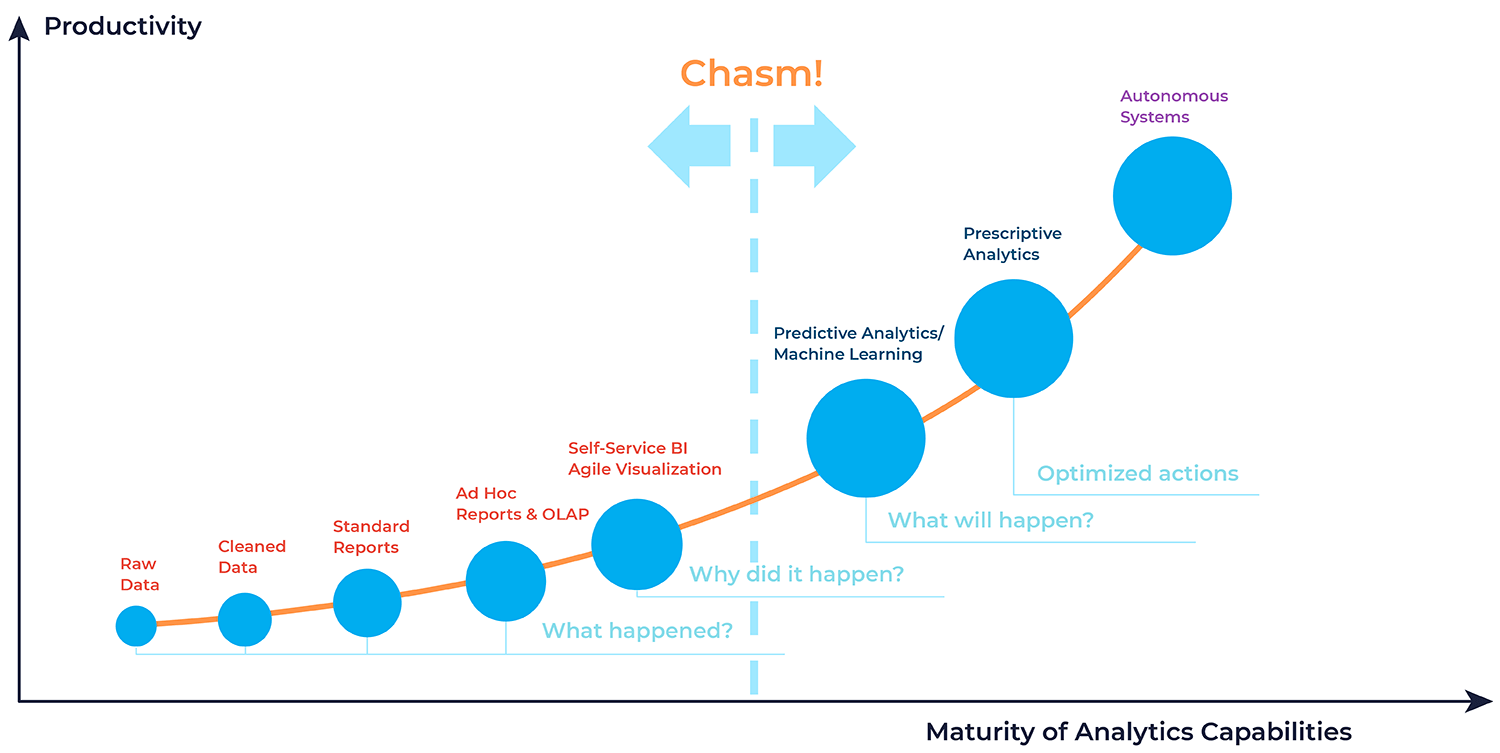
Nível 1: Descritivo
Combinaremos os três primeiros itens em um bloco: dados brutos e limpos e relatórios padrão. Este é o nível mais baixo de processamento de dados, que é mais frequentemente feito no Planilhas Google ou Excel.
Então, nossa barbearia começou a coletar dados sobre clientes que vêm para cortes de cabelo e a contar as visitas. O administrador insere as informações manualmente, e alguns dados são retirados do formulário de registro no site. O gerente pode limpar os dados de duplicatas, corrigir erros cometidos durante o registro e estruturar os dados pelo número e variedade de serviços fornecidos mensalmente.
Com base nisso, você pode criar relatórios simples. Descubra se o número de clientes está aumentando de mês para mês, o que trouxe mais receita no verão – barba e cortes de cabelo.
Esses dados respondem à pergunta: o que aconteceu? Hipóteses podem ser formuladas, e decisões podem ser tomadas com base nelas. Na maioria das vezes, isso é feito manualmente e com os esforços cognitivos do gerente.
Este nível também inclui formatos de análise como relatórios Ad hoc e OLAP. Relatórios ad hoc são relatórios feitos para uma solicitação comercial específica. Normalmente, isso é algo não padrão que está fora dos relatórios regulares. Por exemplo, o gerente “The Barbershop” determina quantas vendas foram feitas ao longo de três meses para um grupo de visitantes carecas, mas barbudos (divididos por dia).
Nível 2: Diagnóstico
Existe a chamada análise self-service (self-service BI) neste nível. Isso implica que especialistas de vários perfis, não apenas analistas de dados, podem consultar os dados necessários e gerar relatórios de resumo. Essa abordagem também usa sistemas de BI como Power BI, Qlik ou Tableau. Especialistas em dados normalmente configuram os painéis nesses sistemas.
Aqui, os dados respondem à pergunta: por que isso aconteceu? Eles descrevem o estado atual da empresa e servem como fonte de conclusões analíticas. Por exemplo, a receita de “The Barbershop” dobrou em comparação ao mês anterior. Os dados mostram que isso aconteceu devido a várias postagens de publicidade sobre a promoção da barbearia.
Neste nível, uma empresa pode migrar de planilhas do Excel para scripts Python e consultas SQL. Além disso, neste ponto, é necessário ter um ou dois analistas de dados na equipe.
Por que migrar para ferramentas mais complexas?
Os motivos podem variar para cada empresa específica:
- Aumento da carga de trabalho com dados. A empresa começou a contabilizar lucros e despesas mensais, coletando dados sobre atividades de marketing, registrando rotatividade de clientes e assim por diante. Multiplicar dezenas de novas planilhas do Excel se torna irracional – é fácil se perder nelas e difícil correlacionar eventos.
- A necessidade de automação. Os funcionários gastam muito tempo coletando dados manualmente. Eles poderiam dedicar esse tempo a um trabalho mais útil para o crescimento do negócio.
- Melhore a qualidade dos dados. Quanto menos automação de processos, mais espaço para erros humanos. Alguns dados podem parar de ser coletados ou ser inseridos com erros. Os sistemas de automação e BI ajudarão a “limpar” melhor os dados e encontrar novas direções para a análise.
- O número de analistas aumentou. Por exemplo, a empresa começou a se desenvolver em várias regiões. Cada região tem seu analista, mas eles devem consolidar os dados em um só lugar. Um único sistema de BI e um repositório comum (ou pelo menos um banco de dados) podem unificar ferramentas e abordagens.

Otimização gratuita de custos de nuvem e gerenciamento aprimorado de recursos de ML/IA para toda a vida
Nível 3: Preditivo e prescritivo
Neste nível, conceitos mais complexos entram em jogo. Este estágio envolve análises preditivas e prescritivas.
No primeiro caso, os dados respondem o que vai acontecer em seguida. Por exemplo, é possível prever o crescimento da receita ou a expansão da base de clientes em seis meses. Aqui, o algoritmo de análise pode ser a base de um modelo de ML.
A análise prescritiva é construída sobre a questão do que otimizar. Os dados mostram que para aumentar a receita da barbearia em 60%, o orçamento de publicidade precisa ser aumentado em 15%.
Neste estágio, não estamos falando de apenas alguns analistas, mas de uma equipe inteira que pode trabalhar em várias direções de negócios. Normalmente, neste ponto, as empresas precisam de plataformas de processamento de dados.
Nível 4
O nível mais avançado é o de sistemas analíticos autônomos baseados em inteligência artificial. Aqui, a máquina propõe uma solução presumivelmente correta com base em análise de big data, e o humano toma a decisão final.
Os bancos podem usar tais sistemas. Por exemplo, estes podem ser sistemas de pontuação de crédito para emitir empréstimos. Nossa barbearia pode usar Lead scoring – uma tecnologia para avaliar o banco de dados de clientes a partir de sua prontidão para comprar os produtos da empresa.
O terceiro e o quarto níveis são apenas para big data?
A resposta curta é não.
O volume de dados não é tão importante quanto as tarefas que a empresa enfrenta
Claro, quanto mais dados, mais representativos os resultados. No entanto, operar com argumentos como “eu só tenho um banco de dados de um milhão de pessoas, todo esse processamento de plataforma não é para mim” também é incorreto.
Pode haver uma pequena quantidade de dados, mas eles podem ser muito diversos: registros de conversas com clientes, imagens de câmeras de vigilância, imagens de usuários, etc. Tudo isso deve ser armazenado sistematicamente para extrair conhecimento valioso e aplicável aos negócios da empresa.
O volume de dados não é tão importante quanto a quantidade de análises e equipes analíticas
Se uma empresa tem várias equipes analíticas para diferentes direções de negócios, isso leva a problemas. As equipes podem usar uma única fonte de dados, mas têm diferentes ferramentas analíticas e sistemas de armazenamento. Às vezes, elas podem analisar a mesma coisa ou calcular o mesmo indicador de forma diferente, o que pode ser mais racional. Se uma nova equipe analítica for adicionada, corre-se o risco de duplicar parte do trabalho já feito.
A heterogeneidade dos pipelines analíticos também leva a atrasos no atendimento aos requisitos de negócios. Um gerente de produto pode pedir para consertar um dashboard com receita de produto, mas a correção pode ser entregue somente em 1,5 mês.
As empresas consideram plataformas de processamento de dados conforme a complexidade das tarefas analíticas e o número de analistas cresce. Elas fornecem uma base comum e convenções aceitas: quais ferramentas usamos para recuperar dados de fontes, onde os armazenamos e como organizamos o armazenamento.
✔️ Embora existam várias maneiras de gerenciar o processamento de dados, o OptScale, a PRIMEIRA plataforma MLOps de CÓDIGO ABERTO, ajuda engenheiros de ML e dados a otimizar o desempenho e os custos de seus experimentos ou tarefas de produção.
A solução está totalmente disponível no Apache 2.0 no GitHub → https://github.com/hystax/optscale.
👆🏻 Desenvolver e treinar modelos de aprendizado de máquina pode ser um processo complexo e demorado, e depurar e analisar o desempenho desses modelos geralmente representa um desafio.
Explore algumas dicas e melhores práticas para superar os principais desafios → https://hystax.com/how-to-debug-and-profile-ml-model-training