Neste artigo, descrevemos o bloco D, dedicado ao fluxo de trabalho automatizado de aprendizado de máquina.
Por favor, encontre o esquema completo, que descreve os principais processos de MLOps aqui. As partes principais do esquema são blocos horizontais, dentro dos quais os aspectos procedimentais dos MLOps são descritos (eles recebem as letras A, B, C, D). Cada um deles é projetado para resolver tarefas específicas dentro da estrutura de garantir a operação ininterrupta dos serviços de ML da empresa.

Desde o início, gostaríamos de mencionar que neste artigo, por sistema ML, queremos dizer um sistema de informação que contém um ou mais componentes com um modelo treinado que executa alguma parte da lógica geral de negócios. Quanto melhor o modelo ML for desenvolvido, maior será o impacto de sua operação. O modelo treinado processa um fluxo de entrada de solicitações e fornece algumas previsões em resposta, automatizando algumas partes do processo de análise ou tomada de decisão.
O processo de usar o modelo para gerar previsões é chamado de inferência, e o processo de treinar o modelo é chamado de treinamento. Uma explicação clara da diferença entre eles pode ser emprestada do Gartner – aqui usaremos gatos como exemplo.
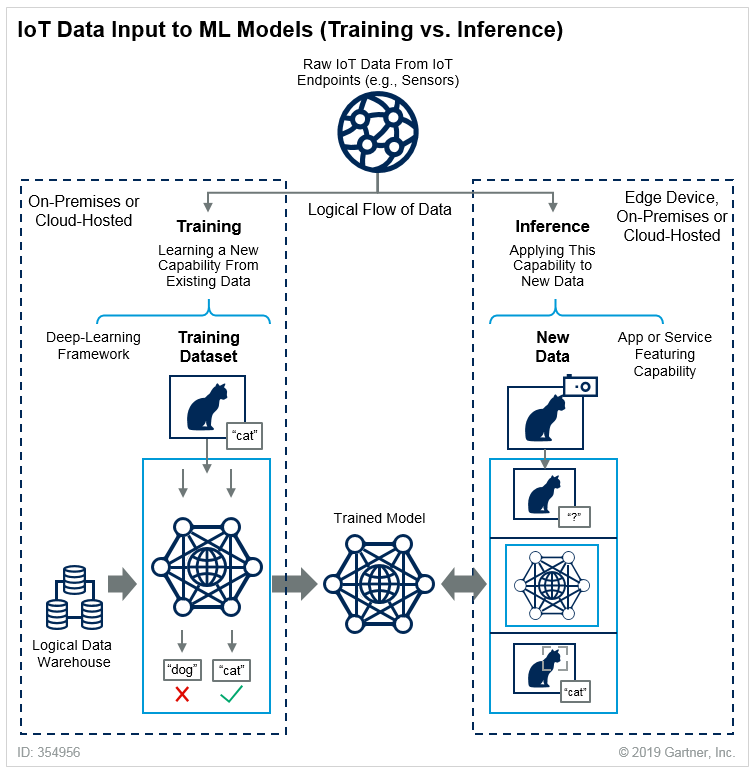
Para o operação eficaz de um sistema de ML de produção, é importante monitorar as métricas de inferência do modelo. Assim que elas começam a declinar, o modelo precisa ser retreinado ou substituído por um novo. Isso geralmente acontece devido a mudanças nos dados de entrada (desvio de dados). Por exemplo, há uma tarefa de negócios em que o modelo pode reconhecer pão em fotos, mas recebe uma foto de um corgi. Os cães no exemplo são para equilíbrio:

O modelo no conjunto de dados inicial não sabia nada sobre corgis, então ele prevê incorretamente. Portanto, o conjunto de dados precisa ser alterado, e novos experimentos precisam ser conduzidos. Ao mesmo tempo, o novo modelo deve ser colocado em produção o mais rápido possível. Os usuários não estão proibidos de enviar imagens de corgis, e eles obterão um resultado errôneo.
Agora, vejamos mais exemplos da vida real: vamos considerar o sistema de recomendação de um marketplace. Com base no histórico de compras de um usuário, compras de usuários semelhantes e outros parâmetros, um modelo ou conjunto de modelos gera um bloco com recomendações. Ele inclui produtos cuja receita de compra é regularmente calculada e rastreada.
Algo acontece, e as necessidades dos compradores mudam. Portanto, as recomendações para eles se tornam desatualizadas, e a demanda pelos produtos recomendados diminui. Tudo isso leva a uma diminuição na receita.
Em seguida, vêm os gritos dos gerentes e as demandas para restaurar tudo até amanhã, o que não leva a nada. Por quê? Não há dados suficientes sobre as novas preferências dos compradores, então você não pode nem criar um novo modelo. Claro, você pode pegar alguns algoritmos básicos de geração de recomendações (filtragem colaborativa baseada em itens) e adicioná-los à produção. Dessa forma, as recomendações funcionarão de alguma forma, mas é apenas um "curativo" temporário.
O ideal é que o processo seja configurado de modo que, com base em métricas e sem a orientação dos gerentes, o processo de retreinamento ou experimentação de diferentes modelos seja iniciado. E o melhor eventualmente substitua o atual em produção. No diagrama, este é o Pipeline de fluxo de trabalho de ML automatizado (bloco D), que é acionado em alguma ferramenta de orquestração.

Otimização gratuita de custos de nuvem e gerenciamento aprimorado de recursos de ML/IA para toda a vida
Esta é provavelmente a seção mais carregada do esquema. A operação do Bloco D envolve vários componentes externos importantes:
- o componente orquestrador de fluxo de trabalho é responsável por lançar o pipeline em um cronograma ou evento especificado
- o armazenamento de recursos fornece dados sobre os recursos necessários para o modelo.
- o registro do modelo e o armazenamento de metadados de ML, onde os modelos e suas métricas obtidas após a conclusão do pipeline lançado são colocados.
A estrutura do bloco combina essencialmente os estágios de experimentação (C) e desenvolvimento de funcionalidades (B2). Isso não é surpreendente, dado que esses processos precisam ser automatizados. As principais diferenças estão nos dois últimos estágios:
- modelo de exportação
- enviar para o registro do modelo
As outras etapas são idênticas às descritas acima.
Vale destacar separadamente o artefatos de serviço necessário pelo orquestrador para lançar os pipelines de retreinamento do modelo. Na verdade, este é um código que é armazenado em um repositório e executado em servidores dedicados. Ele é versionado e modernizado de acordo com todas as regras de desenvolvimento de software. É este código que implementa o pipeline de retreinamento do modelo, e o resultado depende de sua correção.
Vale a pena notar que automatizar experimentos em geral é impossível. Claro, você pode adicionar o conceito de AutoML ao processo, mas até o momento, não há nenhuma solução reconhecida que possa ser usada com os mesmos resultados para qualquer tópico de experimento.
Em geral, O AutoML funciona da seguinte maneira:
- De alguma forma, ele forma um conjunto de combinações de parâmetros operacionais do modelo.
- Ele inicia um experimento para cada combinação resultante.
- Ele registra as métricas de cada experimento, com base nas quais o melhor modelo é selecionado.
Em essência, o AutoML executa todas as manipulações que um hipotético Cientista de Dados Júnior/Médio executaria em um círculo de tarefas mais ou menos padrão.
Nós cobrimos um pouco a automação. Em seguida, é necessário organizar a entrega da nova versão do modelo para a produção.
💡 Você também pode se interessar pelo nosso artigo 'Principais processos de MLOps (parte 2): Engenharia de funcionalidades ou desenvolvimento de funcionalidades' → https://hystax.com/key-mlops-processes-part-2-feature-engineering-or-the-development-of-features.
✔️ OptScale, uma plataforma de código aberto FinOps & MLOps, que ajuda empresas a otimizar custos de nuvem e trazer mais transparência ao uso da nuvem, está totalmente disponível no Apache 2.0 no GitHub → https://github.com/hystax/optscale.




