Se você lê regularmente artigos sobre MLOps, começa a formar uma certa percepção do contexto. Assim, os autores dos textos escrevem principalmente sobre trabalhar com três tipos de artefatos:
- Dados,
- Modelo,
- Código.
Em geral, isso é o suficiente para explicar a essência do MLOps. A equipe de ML deve criar uma base de código pela qual implementar um processo automatizado e repetível:
- Treinamento em conjuntos de dados de qualidade para novas versões de modelos de ML,
- Entregar versões atualizadas dos modelos aos serviços do cliente final para lidar com as solicitações recebidas.
Vamos agora detalhar esses aspectos.
Dados
Se você lê regularmente artigos sobre MLOps, começa a formar uma certa percepção do contexto. Assim, os autores dos textos escrevem principalmente sobre trabalhar com três tipos de artefatos:
- Dados,
- Modelo,
- Código.
Em geral, isso é o suficiente para explicar a essência do MLOps. A equipe de ML deve criar uma base de código pela qual implementar um processo automatizado e repetível:
- Treinamento em conjuntos de dados de qualidade para novas versões de modelos de ML,
- Entregar versões atualizadas dos modelos aos serviços do cliente final para lidar com as solicitações recebidas.
Vamos agora detalhar esses aspectos.
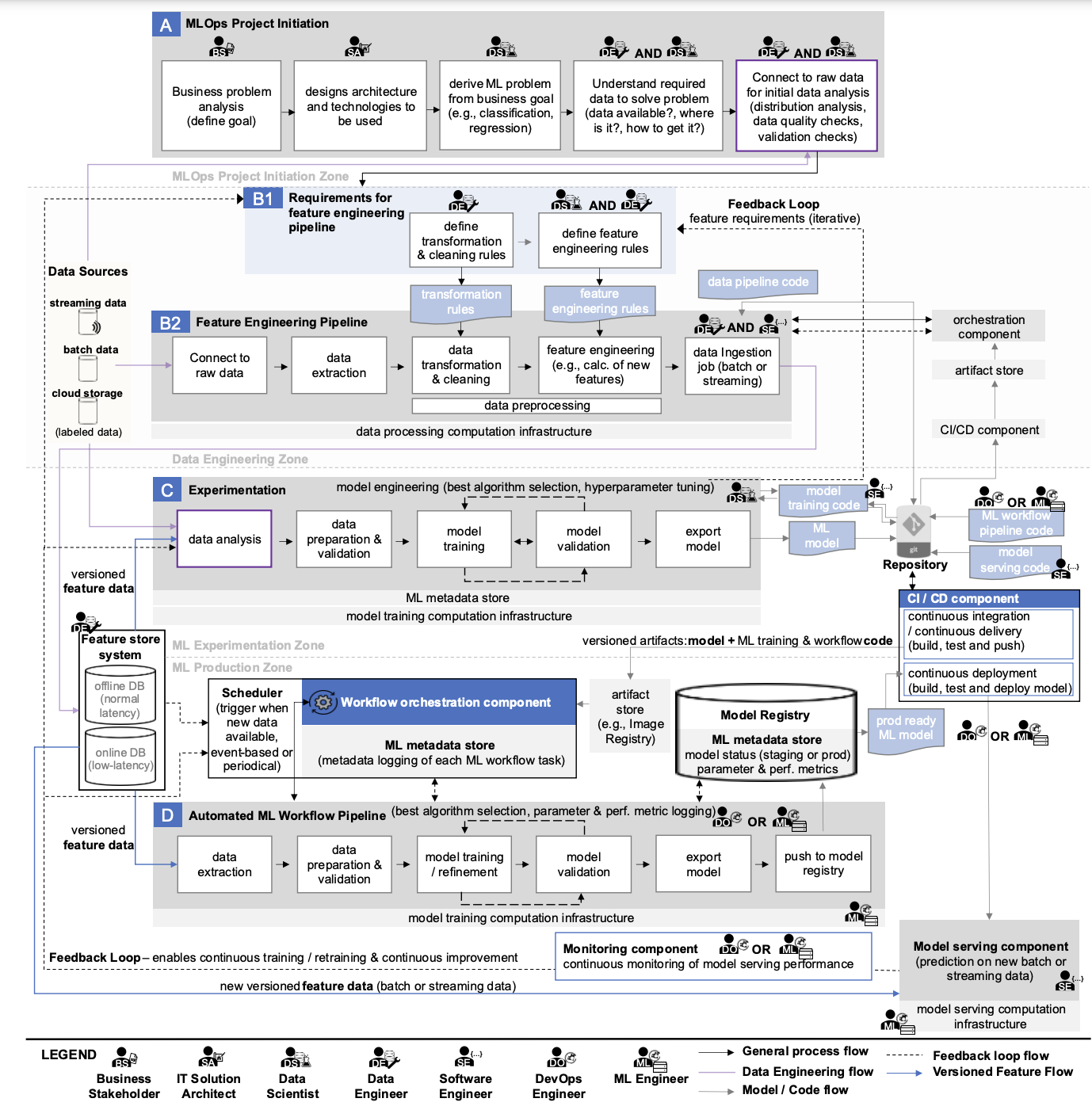
Se você observar atentamente o diagrama que examinamos em detalhes no texto anterior, você pode encontrar as seguintes “fontes de dados”:
- Transmissão de dados,
- Dados em lote,
- Dados em nuvem,
- Dados rotulados,
- Recurso DB online,
- Recurso DB offline.
É controverso chamar essa lista de fontes, mas a ideia conceitual deve ser clara. Há dados armazenados em um grande número de sistemas e processados de forma diferente. Todos eles podem ser necessários para um modelo de ML.
O que fazer para obter os dados necessários no sistema ML:
- Use ferramentas e processos que permitam recuperar dados de fontes, criar conjuntos de dados a partir deles e expandi-los com novos recursos, que são então salvos nos bancos de dados correspondentes para uso geral,
- Implementar ferramentas de monitoramento e controle porque a qualidade dos dados pode mudar,
- Adicione um catálogo que simplifique a pesquisa de dados se houver muitos.
Como resultado, a empresa pode ter uma plataforma de dados completa com ETL/ELT, barramentos de dados, armazenamentos de objetos e outros Greenplum.
O aspecto principal do uso de dados em MLOps é a automação da preparação de conjuntos de dados de alta qualidade para treinamento de modelos de ML.

Otimização gratuita de custos de nuvem e gerenciamento aprimorado de recursos de ML/IA para toda a vida
Modelo
Agora vamos procurar artefatos no diagrama que se relacionam aos modelos de ML:
- modelo ML,
- Modelo de ML pronto para produção,
- Registro de Modelo,
- Armazenamento de metadados ML,
- Componente de serviço do modelo,
- Componente de monitoramento de modelo.
Também precisamos de ferramentas que ajudem a:
- Encontre os melhores parâmetros dos modelos de ML conduzindo vários experimentos,
- Salvar os melhores modelos e informações suficientes sobre eles em um registro especial (para que os resultados dos experimentos possam ser reproduzidos no futuro),
- Organizar a entrega dos melhores modelos aos serviços do cliente final,
- Realizar monitoramento de qualidade do seu trabalho para que, se necessário, novos modelos possam ser treinados automaticamente.
O aspecto principal de trabalhar com modelos em MLOps é a automação do processo de retreinamento de modelos para obter melhores métricas de qualidade de seu trabalho com solicitações de clientes.
Código
O código facilita as coisas: ele automatiza processos para trabalhar com dados e modelos.
No diagrama acima, você pode encontrar referências a:
- Regras de transformação de dados,
- Regras de engenharia de recursos,
- Código de pipeline de dados,
- Código de treinamento do modelo,
- Código de fluxo de trabalho de aprendizado de máquina (ML),
- Modelo de código de serviço.
Além disso, a infraestrutura como código (IaaC) pode ser adicionada para configurar toda a infraestrutura necessária.
Vale a pena notar que às vezes pode haver código adicional para orquestração, especialmente se vários orquestradores forem usados na equipe. Por exemplo, o Airflow pode ser usado para iniciar DAGs no Dagster.
Infraestrutura para MLOps
No diagrama, vemos vários tipos de infraestrutura computacional utilizados:
- Infraestrutura computacional de processamento de dados,
- Infraestrutura computacional de treinamento de modelos,
- Modelo que atende infraestrutura computacional.
O último é usado tanto para conduzir experimentos quanto para retreinar modelos dentro de pipelines automatizados. Essa abordagem é possível se a utilização de infraestrutura computacional tiver capacidade suficiente para executar esses processos simultaneamente.
Nos estágios iniciais, todas as tarefas podem ser resolvidas dentro de uma infraestrutura, mas no futuro, a necessidade de novos recursos crescerá, principalmente devido aos requisitos específicos para as configurações de recursos computacionais:
- Para treinar e reciclar modelos, não é necessário usar a GPU Tesla A100 mais potente; uma opção mais simples como a Tesla A30 ou placas da série RTX A (A2000, A4000, A5000) podem ser selecionadas.
- Para servir, a Nvidia tem a GPU Tesla A2, que é adequada se o seu modelo e lote de dados para processamento não excederem o tamanho da sua memória de vídeo; se isso acontecer, selecione uma das GPUs no primeiro ponto.
- Para processamento de dados, uma placa de vídeo pode não ser necessária, já que esse processo pode ser construído em uma CPU. No entanto, a escolha aqui é ainda mais difícil; AMD Epyc, Intel Xeon Gold ou processadores de desktop modernos podem ser considerados.
A adoção generalizada do Kubernetes como uma plataforma de infraestrutura para sistemas ML adiciona complexidade. Todos os recursos computacionais devem ser capazes de serem usados no k8s.
Portanto, o panorama geral do MLOps é apenas o nível mais alto de abstração que precisa ser tratado.
MLOps razoáveis e de média escala
Depois de considerar um diagrama tão extenso e artefatos mencionados, o desejo de construir algo semelhante em sua própria empresa pode desaparecer. É necessário escolher e implementar muitas ferramentas, preparar a infraestrutura necessária para elas, ensinar a equipe a trabalhar com tudo isso e também manter tudo isso acima.
O principal neste negócio é começar. Não é necessário implementar todos os componentes do MLOps de uma vez se não houver necessidade comercial para eles. Usando modelos de maturidade, uma fundação pode ser criada em torno da qual uma plataforma ML se desenvolverá no futuro.
É bem possível que muitos componentes nunca sejam necessários para atingir objetivos de negócios. Essa ideia já é ativamente promovida em vários artigos sobre MLOps razoáveis e de média escala.
💡Como a maioria dos processos de TI, o MLOps possui níveis de maturidade. Eles ajudam as empresas a entender em que ponto do processo de desenvolvimento estão e o que precisa ser mudado.
Você também pode se interessar pelo nosso artigo 'Níveis de maturidade de MLOps: os modelos mais conhecidos' → https://hystax.com/mlops-maturity-levels-the-most-well-known-models.
✔️ OptScale, uma plataforma de código aberto FinOps & MLOps, ajuda empresas a executar ML/AI ou qualquer tipo de carga de trabalho com desempenho e custo de infraestrutura ideais. A plataforma está totalmente disponível sob Apache 2.0 no GitHub. Otimize os gastos com a nuvem e obtenha uma visão completa dos recursos de nuvem utilizados e seus detalhes de uso → https://github.com/hystax/optscale.



